 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying the Context Shift between Test Benchmarks and Production Data
Paper and Code
Jul 03, 2022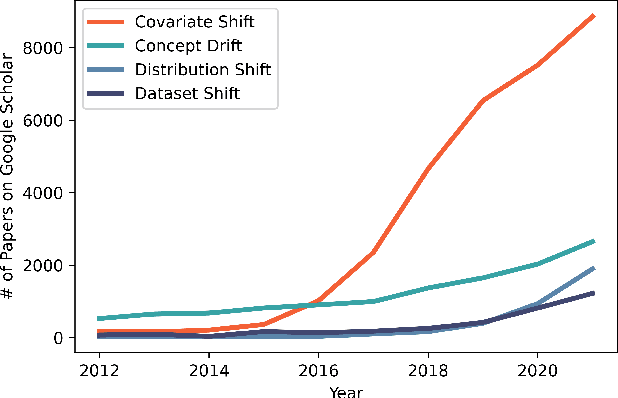
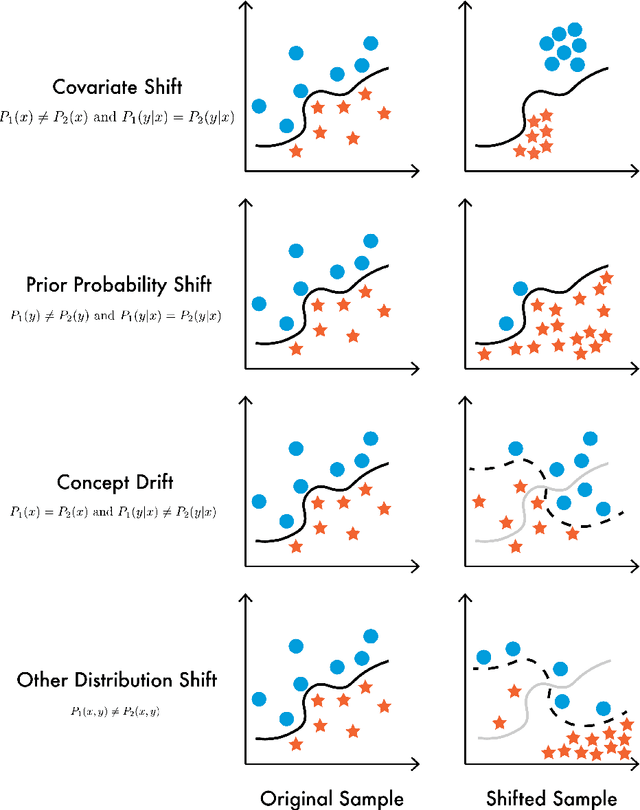

Across a wide variety of domains, there exists a performance gap between machine learning models' accuracy on dataset benchmarks and real-world production data. Despite the careful design of static dataset benchmarks to represent the real-world, models often err when the data is out-of-distribution relative to the data the models have been trained on. We can directly measure and adjust for some aspects of distribution shift, but we cannot address sample selection bias, adversarial perturbations, and non-stationarity without knowing the data generation process. In this paper, we outline two methods for identifying changes in context that lead to distribution shifts and model prediction errors: leveraging human intuition and expert knowledge to identify first-order contexts and developing dynamic benchmarks based on desiderata for the data generation process. Furthermore, we present two case-studies to highlight the implicit assumptions underlying applied machine learning models that tend to lead to errors when attempting to generalize beyond test benchmark datasets. By paying close attention to the role of context in each prediction task, researchers can reduce context shift errors and increase generalization performance.