 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICLEF: In-Context Learning with Expert Feedback for Explainable Style Transfer
Paper and Code
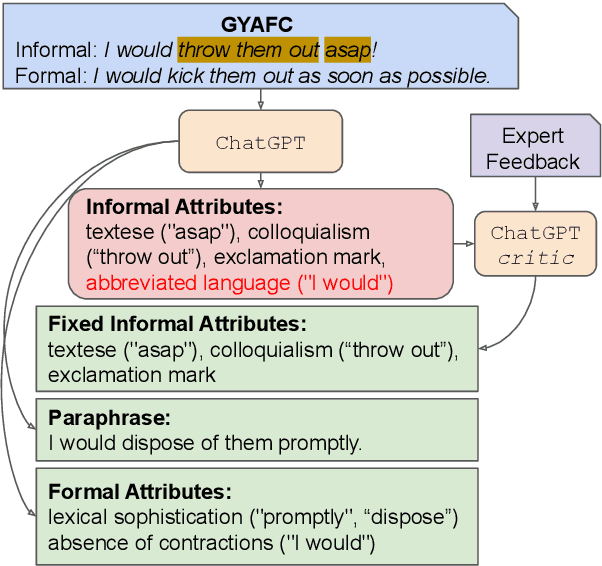
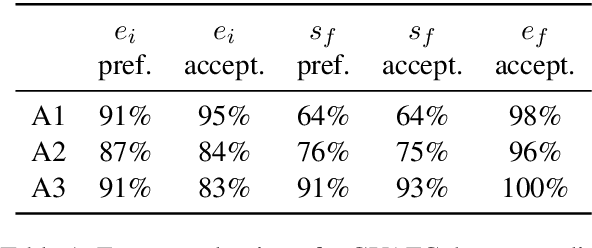
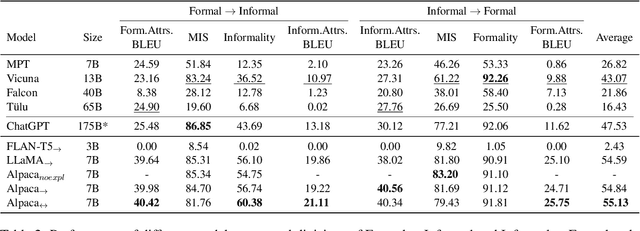

While state-of-the-art language models excel at the style transfer task, current work does not address explainability of style transfer systems. Explanations could be generated using large language models such as GPT-3.5 and GPT-4, but the use of such complex systems is inefficient when smaller, widely distributed, and transparent alternatives are available. We propose a framework to augment and improve a formality style transfer dataset with explanations via model distillation from ChatGPT. To further refine the generated explanations, we propose a novel way to incorporate scarce expert human feedback using in-context learning (ICLEF: In-Context Learning from Expert Feedback) by prompting ChatGPT to act as a critic to its own outputs. We use the resulting dataset of 9,960 explainable formality style transfer instances (e-GYAFC) to show that current openly distributed instruction-tuned models (and, in some settings, ChatGPT) perform poorly on the task, and that fine-tuning on our high-quality dataset leads to significant improvements as shown by automatic evaluation. In human evaluation, we show that models much smaller than ChatGPT fine-tuned on our data align better with expert preferences. Finally, we discuss two potential applications of models fine-tuned on the explainable style transfer task: interpretable authorship verification and interpretable adversarial attacks on AI-generated text detectors.