 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiCAN: Instance-Centric Attention Network for Human-Object Interaction Detection
Paper and Code



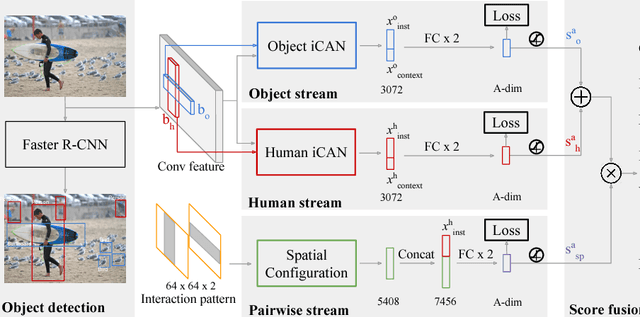
Recent years have witnessed rapid progress in detecting and recognizing individual object instances. To understand the situation in a scene, however, computers need to recognize how humans interact with surrounding objects. In this paper, we tackle the challenging task of detecting human-object interactions (HOI). Our core idea is that the appearance of a person or an object instance contains informative cues on which relevant parts of an image to attend to for facilitating interaction prediction. To exploit these cues, we propose an instance-centric attention module that learns to dynamically highlight regions in an image conditioned on the appearance of each instance. Such an attention-based network allows us to selectively aggregate features relevant for recognizing HOIs. We validate the efficacy of the proposed network on the Verb in COCO and HICO-DET datasets and show that our approach compares favorably with the state-of-the-arts.