 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperplane bounds for neural feature mappings
Paper and Code
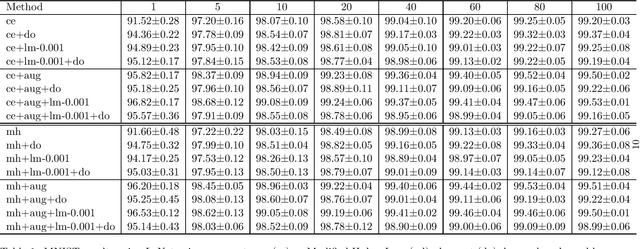

Deep learning methods minimise the empirical risk using loss functions such as the cross entropy loss. When minimising the empirical risk, the generalisation of the learnt function still depends on the performance on the training data, the Vapnik-Chervonenkis(VC)-dimension of the function and the number of training examples. Neural networks have a large number of parameters, which correlates with their VC-dimension that is typically large but not infinite, and typically a large number of training instances are needed to effectively train them. In this work, we explore how to optimize feature mappings using neural network with the intention to reduce the effective VC-dimension of the hyperplane found in the space generated by the mapping. An interpretation of the results of this study is that it is possible to define a loss that controls the VC-dimension of the separating hyperplane. We evaluate this approach and observe that the performance when using this method improves when the size of the training set is small.