 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypernymy Understanding Evaluation of Text-to-Image Models via WordNet Hierarchy
Paper and Code



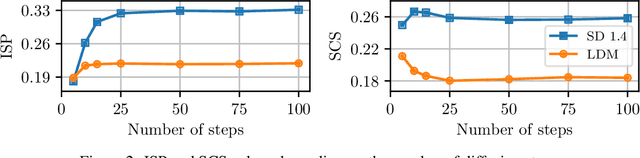
Text-to-image synthesis has recently attracted widespread attention due to rapidly improving quality and numerous practical applications. However, the language understanding capabilities of text-to-image models are still poorly understood, which makes it difficult to reason about prompt formulations that a given model would understand well. In this work, we measure the capability of popular text-to-image models to understand $\textit{hypernymy}$, or the "is-a" relation between words. We design two automatic metrics based on the WordNet semantic hierarchy and existing image classifiers pretrained on ImageNet. These metrics both enable broad quantitative comparison of linguistic capabilities for text-to-image models and offer a way of finding fine-grained qualitative differences, such as words that are unknown to models and thus are difficult for them to draw. We comprehensively evaluate popular text-to-image models, including GLIDE, Latent Diffusion, and Stable Diffusion, showing how our metrics can provide a better understanding of the individual strengths and weaknesses of these models.