 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper: Distributed Cloud Processing for Large-Scale Deep Learning Tasks
Paper and Code
Oct 16, 2019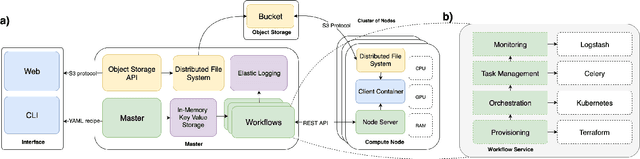
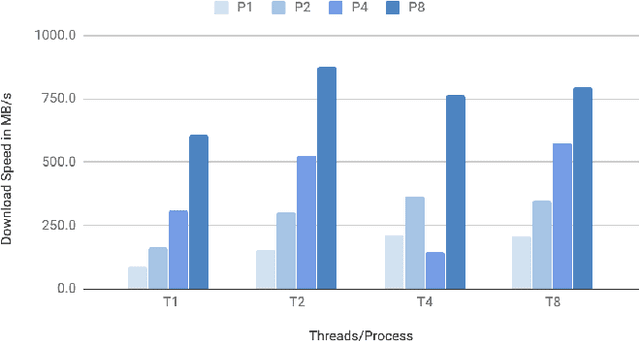


Training and deploying deep learning models in real-world applications require processing large amounts of data. This is a challenging task when the amount of data grows to a hundred terabytes, or even, petabyte-scale. We introduce a hybrid distributed cloud framework with a unified view to multiple clouds and an on-premise infrastructure for processing tasks using both CPU and GPU compute instances at scale. The system implements a distributed file system and failure-tolerant task processing scheduler, independent of the language and Deep Learning framework used. It allows to utilize unstable cheap resources on the cloud to significantly reduce costs. We demonstrate the scalability of the framework on running pre-processing, distributed training, hyperparameter search and large-scale inference tasks utilizing 10,000 CPU cores and 300 GPU instances with the overall processing power of 30 petaflops.