 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centered Unsupervised Segmentation Fusion
Paper and Code
Jul 22, 2020
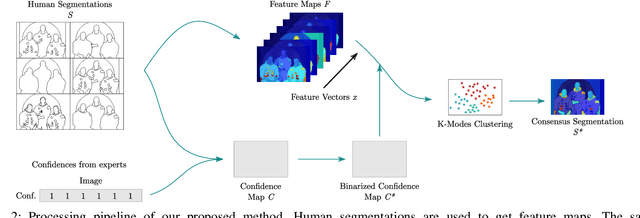
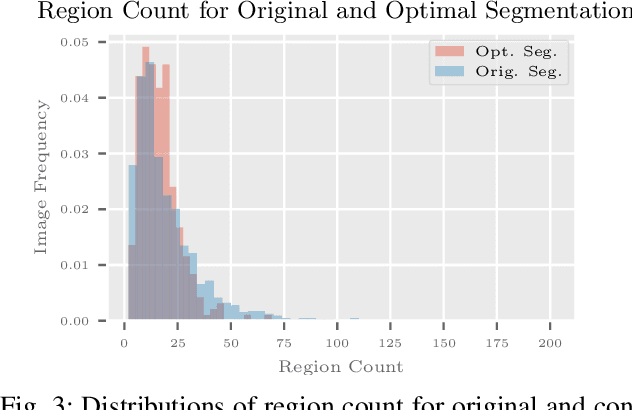

Segmentation is generally an ill-posed problem since it results in multiple solutions and is, therefore, hard to define ground truth data to evaluate algorithms. The problem can be naively surpassed by using only one annotator per image, but such acquisition doesn't represent the cognitive perception of an image by the majority of people. Nowadays, it is not difficult to obtain multiple segmentations with crowdsourcing, so the only problem that stays is how to get one ground truth segmentation per image. There already exist numerous algorithmic solutions, but most methods are supervised or don't consider confidence per human segmentation. In this paper, we introduce a new segmentation fusion model that is based on K-Modes clustering. Results obtained from publicly available datasets with human ground truth segmentations clearly show that our model outperforms the state-of-the-art on human segmentations.