 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Algorithm Collaboration: Achieving Complementarity and Avoiding Unfairness
Paper and Code
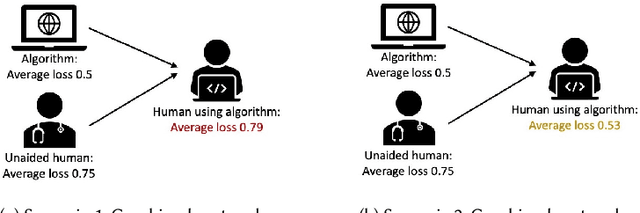
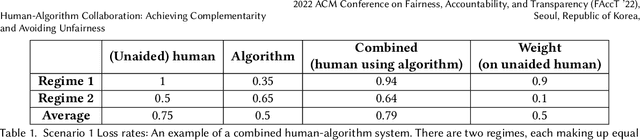

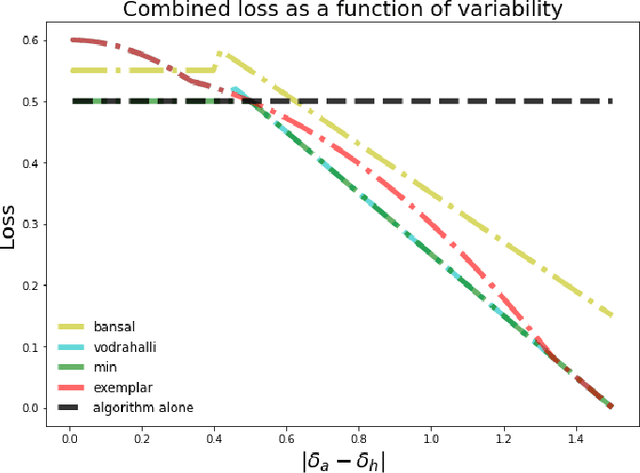
Much of machine learning research focuses on predictive accuracy: given a task, create a machine learning model (or algorithm) that maximizes accuracy. In many settings, however, the final prediction or decision of a system is under the control of a human, who uses an algorithm's output along with their own personal expertise in order to produce a combined prediction. One ultimate goal of such collaborative systems is "complementarity": that is, to produce lower loss (equivalently, greater payoff or utility) than either the human or algorithm alone. However, experimental results have shown that even in carefully-designed systems, complementary performance can be elusive. Our work provides three key contributions. First, we provide a theoretical framework for modeling simple human-algorithm systems and demonstrate that multiple prior analyses can be expressed within it. Next, we use this model to prove conditions where complementarity is impossible, and give constructive examples of where complementarity is achievable. Finally, we discuss the implications of our findings, especially with respect to the fairness of a classifier. In sum, these results deepen our understanding of key factors influencing the combined performance of human-algorithm systems, giving insight into how algorithmic tools can best be designed for collaborative environments.