 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuBERT-TR: Reviving Turkish Automatic Speech Recognition with Self-supervised Speech Representation Learning
Paper and Code
Oct 13, 2022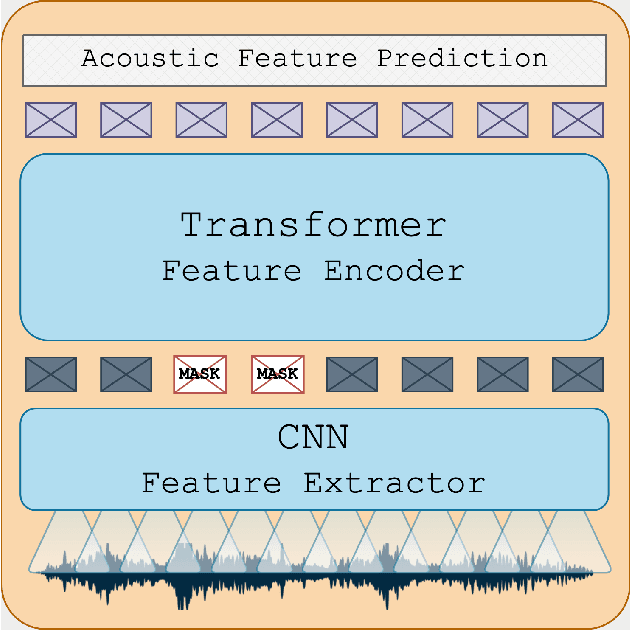
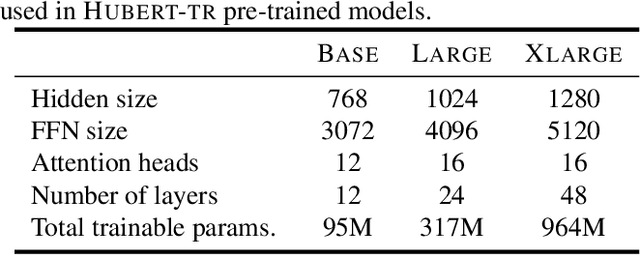
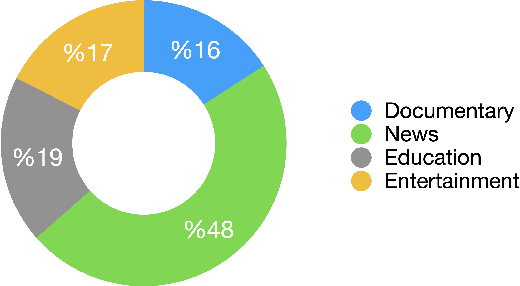
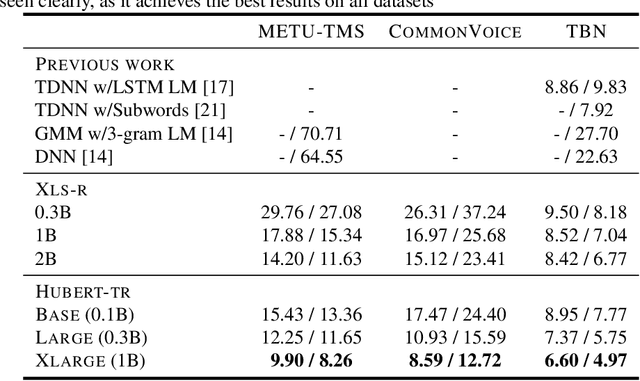
While the Turkish language is listed among low-resource languages, literature on Turkish automatic speech recognition (ASR) is relatively old. In this paper, we present HuBERT-TR, a speech representation model for Turkish based on HuBERT. HuBERT-TR achieves state-of-the-art results on several Turkish ASR datasets. We investigate pre-training HuBERT for Turkish with large-scale data curated from online resources. We pre-train HuBERT-TR using over 6,500 hours of speech data curated from YouTube that includes extensive variability in terms of quality and genre. We show that pre-trained models within a multi-lingual setup are inferior to language-specific models, where our Turkish model HuBERT-TR base performs better than its x10 times larger multi-lingual counterpart XLS-R-1B. Moreover, we study the effect of scaling on ASR performance by scaling our models up to 1B parameters. Our best model yields a state-of-the-art word error rate of 4.97% on the Turkish Broadcast News dataset. Models are available at huggingface.co/asafaya .