 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to tune the RBF SVM hyperparameters?: An empirical evaluation of 18 search algorithms
Paper and Code
Aug 26, 2020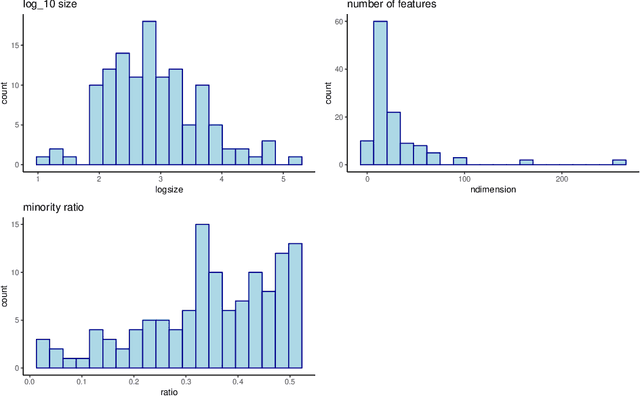

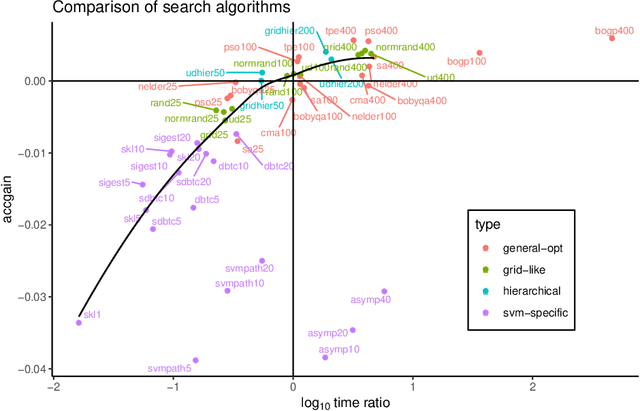
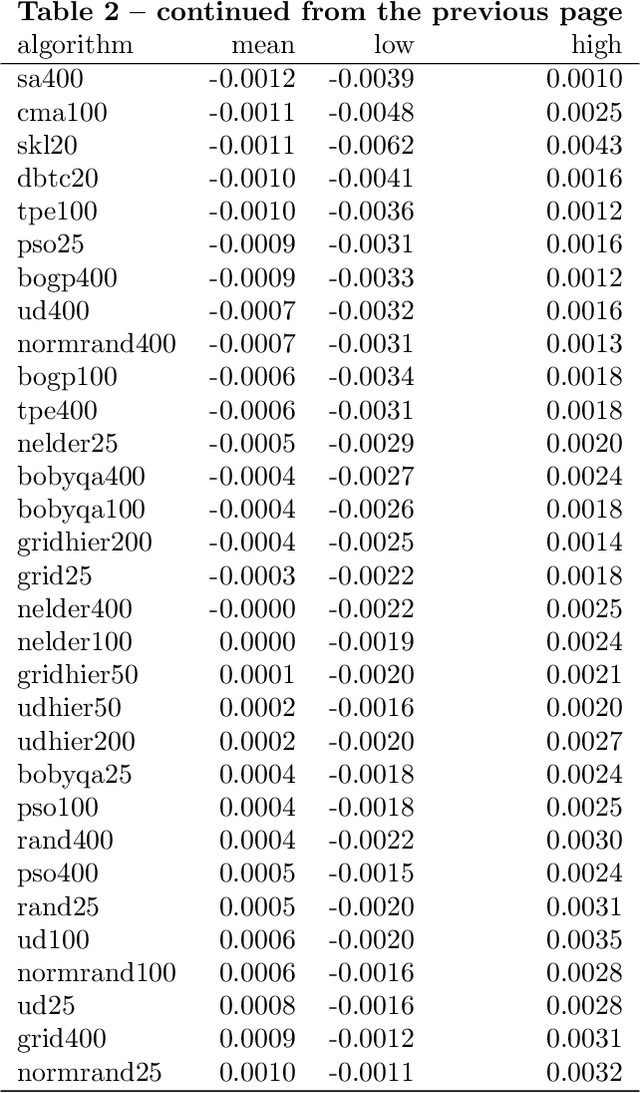
SVM with an RBF kernel is usually one of the best classification algorithms for most data sets, but it is important to tune the two hyperparameters $C$ and $\gamma$ to the data itself. In general, the selection of the hyperparameters is a non-convex optimization problem and thus many algorithms have been proposed to solve it, among them: grid search, random search, Bayesian optimization, simulated annealing, particle swarm optimization, Nelder Mead, and others. There have also been proposals to decouple the selection of $\gamma$ and $C$. We empirically compare 18 of these proposed search algorithms (with different parameterizations for a total of 47 combinations) on 115 real-life binary data sets. We find (among other things) that trees of Parzen estimators and particle swarm optimization select better hyperparameters with only a slight increase in computation time with respect to a grid search with the same number of evaluations. We also find that spending too much computational effort searching the hyperparameters will not likely result in better performance for future data and that there are no significant differences among the different procedures to select the best set of hyperparameters when more than one is found by the search algorithms.