 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to tackle an emerging topic? Combining strong and weak labels for Covid news NER
Paper and Code

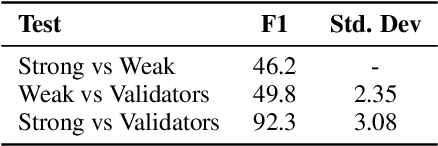

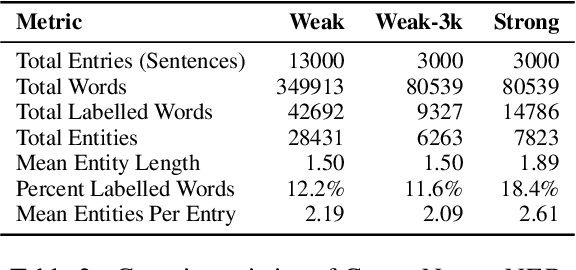
Being able to train Named Entity Recognition (NER) models for emerging topics is crucial for many real-world applications especially in the medical domain where new topics are continuously evolving out of the scope of existing models and datasets. For a realistic evaluation setup, we introduce a novel COVID-19 news NER dataset (COVIDNEWS-NER) and release 3000 entries of hand annotated strongly labelled sentences and 13000 auto-generated weakly labelled sentences. Besides the dataset, we propose CONTROSTER, a recipe to strategically combine weak and strong labels in improving NER in an emerging topic through transfer learning. We show the effectiveness of CONTROSTER on COVIDNEWS-NER while providing analysis on combining weak and strong labels for training. Our key findings are: (1) Using weak data to formulate an initial backbone before tuning on strong data outperforms methods trained on only strong or weak data. (2) A combination of out-of-domain and in-domain weak label training is crucial and can overcome saturation when being training on weak labels from a single source.