 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Evaluate the Quality of Unsupervised Anomaly Detection Algorithms?
Paper and Code
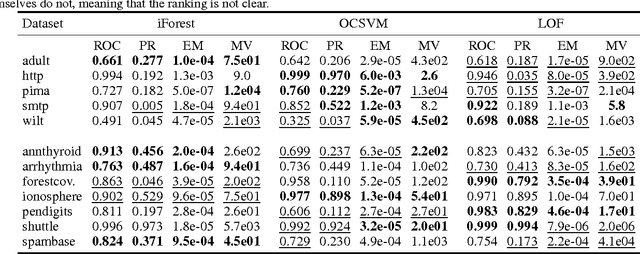
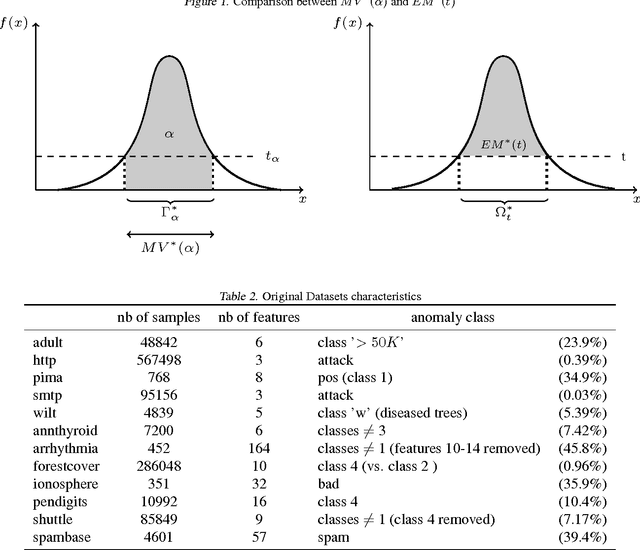
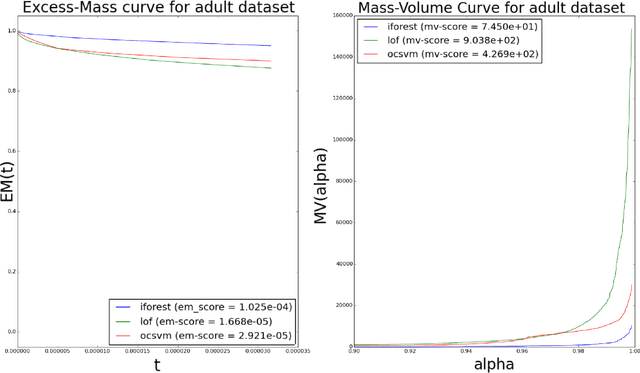
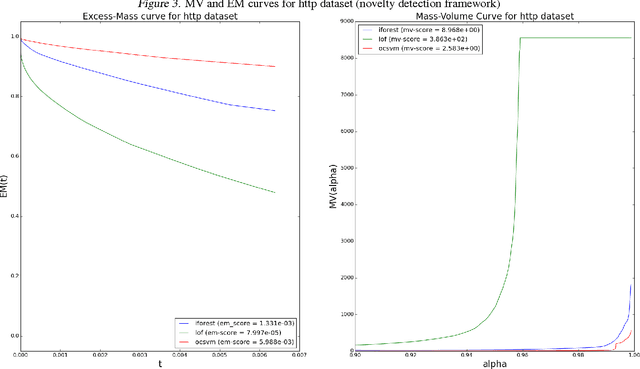
When sufficient labeled data are available, classical criteria based on Receiver Operating Characteristic (ROC) or Precision-Recall (PR) curves can be used to compare the performance of un-supervised anomaly detection algorithms. However , in many situations, few or no data are labeled. This calls for alternative criteria one can compute on non-labeled data. In this paper, two criteria that do not require labels are empirically shown to discriminate accurately (w.r.t. ROC or PR based criteria) between algorithms. These criteria are based on existing Excess-Mass (EM) and Mass-Volume (MV) curves, which generally cannot be well estimated in large dimension. A methodology based on feature sub-sampling and aggregating is also described and tested, extending the use of these criteria to high-dimensional datasets and solving major drawbacks inherent to standard EM and MV curves.