 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Robust are Model Rankings: A Leaderboard Customization Approach for Equitable Evaluation
Paper and Code
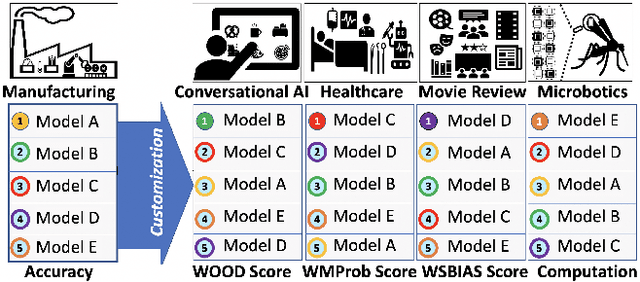
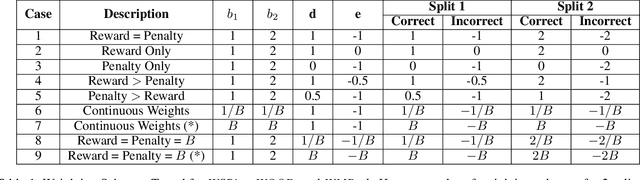
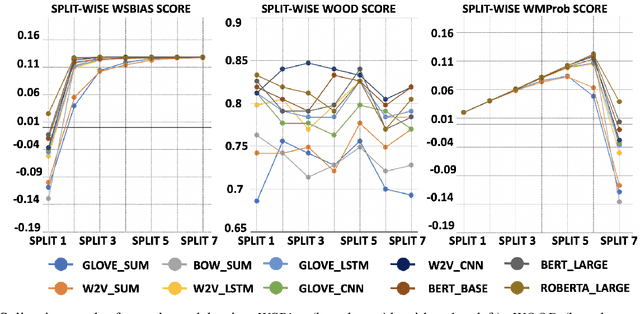
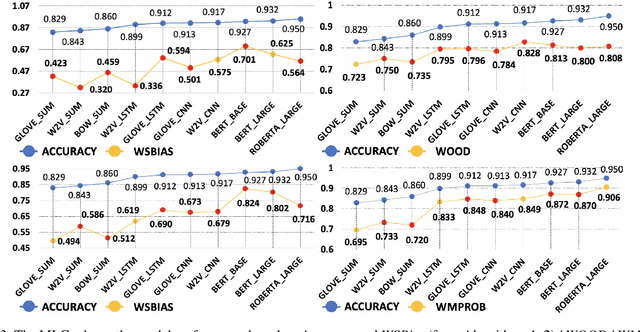
Models that top leaderboards often perform unsatisfactorily when deployed in real world applications; this has necessitated rigorous and expensive pre-deployment model testing. A hitherto unexplored facet of model performance is: Are our leaderboards doing equitable evaluation? In this paper, we introduce a task-agnostic method to probe leaderboards by weighting samples based on their `difficulty' level. We find that leaderboards can be adversarially attacked and top performing models may not always be the best models. We subsequently propose alternate evaluation metrics. Our experiments on 10 models show changes in model ranking and an overall reduction in previously reported performance -- thus rectifying the overestimation of AI systems' capabilities. Inspired by behavioral testing principles, we further develop a prototype of a visual analytics tool that enables leaderboard revamping through customization, based on an end user's focus area. This helps users analyze models' strengths and weaknesses, and guides them in the selection of a model best suited for their application scenario. In a user study, members of various commercial product development teams, covering 5 focus areas, find that our prototype reduces pre-deployment development and testing effort by 41% on average.