 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow inter-rater variability relates to aleatoric and epistemic uncertainty: a case study with deep learning-based paraspinal muscle segmentation
Paper and Code
Aug 14, 2023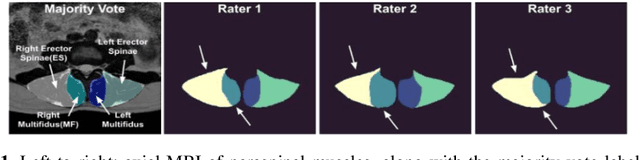



Recent developments in deep learning (DL) techniques have led to great performance improvement in medical image segmentation tasks, especially with the latest Transformer model and its variants. While labels from fusing multi-rater manual segmentations are often employed as ideal ground truths in DL model training, inter-rater variability due to factors such as training bias, image noise, and extreme anatomical variability can still affect the performance and uncertainty of the resulting algorithms. Knowledge regarding how inter-rater variability affects the reliability of the resulting DL algorithms, a key element in clinical deployment, can help inform better training data construction and DL models, but has not been explored extensively. In this paper, we measure aleatoric and epistemic uncertainties using test-time augmentation (TTA), test-time dropout (TTD), and deep ensemble to explore their relationship with inter-rater variability. Furthermore, we compare UNet and TransUNet to study the impacts of Transformers on model uncertainty with two label fusion strategies. We conduct a case study using multi-class paraspinal muscle segmentation from T2w MRIs. Our study reveals the interplay between inter-rater variability and uncertainties, affected by choices of label fusion strategies and DL models.