 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow good are deep models in understanding the generated images?
Paper and Code
Aug 25, 2022
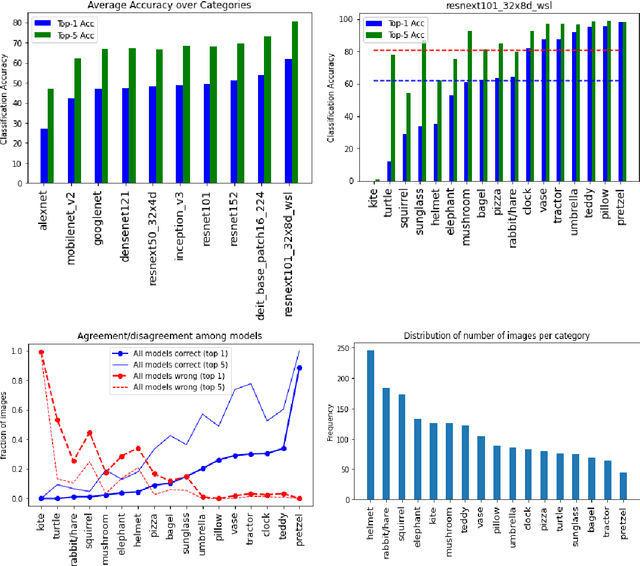


My goal in this paper is twofold: to study how well deep models can understand the images generated by DALL-E 2 and Midjourney, and to quantitatively evaluate these generative models. Two sets of generated images are collected for object recognition and visual question answering (VQA) tasks. On object recognition, the best model, out of 10 state-of-the-art object recognition models, achieves about 60\% and 80\% top-1 and top-5 accuracy, respectively. These numbers are much lower than the best accuracy on the ImageNet dataset (91\% and 99\%). On VQA, the OFA model scores 77.3\% on answering 241 binary questions across 50 images. This model scores 94.7\% on the binary VQA-v2 dataset. Humans are able to recognize the generated images and answer questions on them easily. We conclude that a) deep models struggle to understand the generated content, and may do better after fine-tuning, and b) there is a large distribution shift between the generated images and the real photographs. The distribution shift appears to be category-dependent. Data is available at: https://drive.google.com/file/d/1n2nCiaXtYJRRF2R73-LNE3zggeU_HeH0/view?usp=sharing.