 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"How Does It Detect A Malicious App?" Explaining the Predictions of AI-based Android Malware Detector
Paper and Code
Nov 06, 2021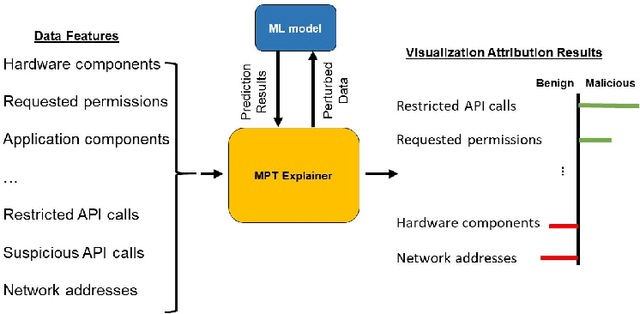
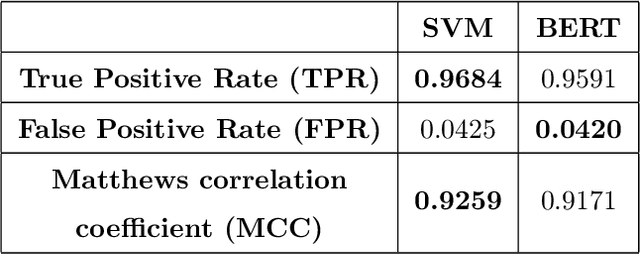
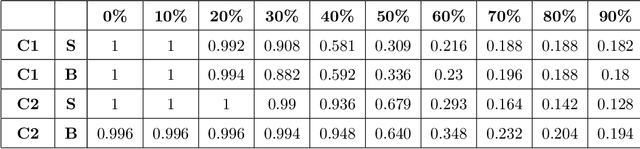
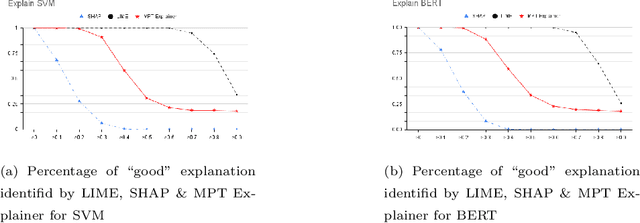
AI methods have been proven to yield impressive performance on Android malware detection. However, most AI-based methods make predictions of suspicious samples in a black-box manner without transparency on models' inference. The expectation on models' explainability and transparency by cyber security and AI practitioners to assure the trustworthiness increases. In this article, we present a novel model-agnostic explanation method for AI models applied for Android malware detection. Our proposed method identifies and quantifies the data features relevance to the predictions by two steps: i) data perturbation that generates the synthetic data by manipulating features' values; and ii) optimization of features attribution values to seek significant changes of prediction scores on the perturbed data with minimal feature values changes. The proposed method is validated by three experiments. We firstly demonstrate that our proposed model explanation method can aid in discovering how AI models are evaded by adversarial samples quantitatively. In the following experiments, we compare the explainability and fidelity of our proposed method with state-of-the-arts, respectively.