Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMM Specialization with Selective Lexicalization
Paper and Code
Dec 23, 1999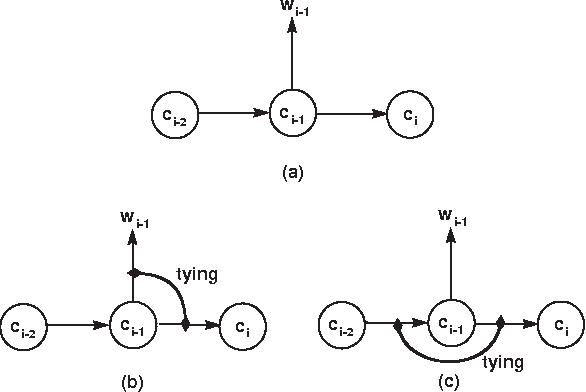
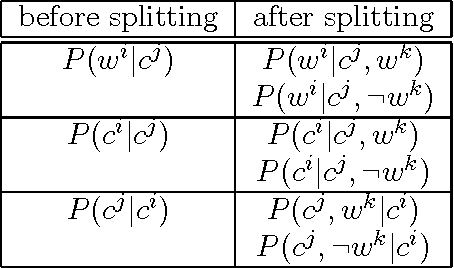
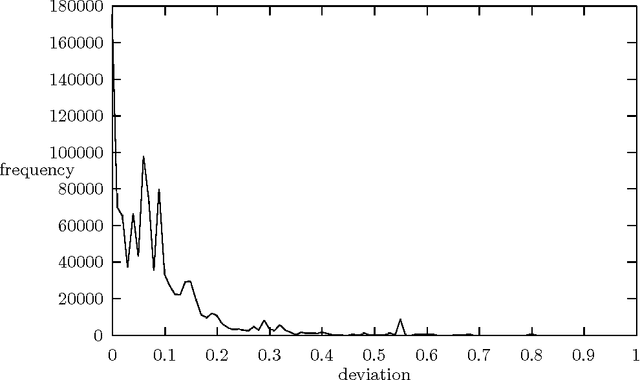
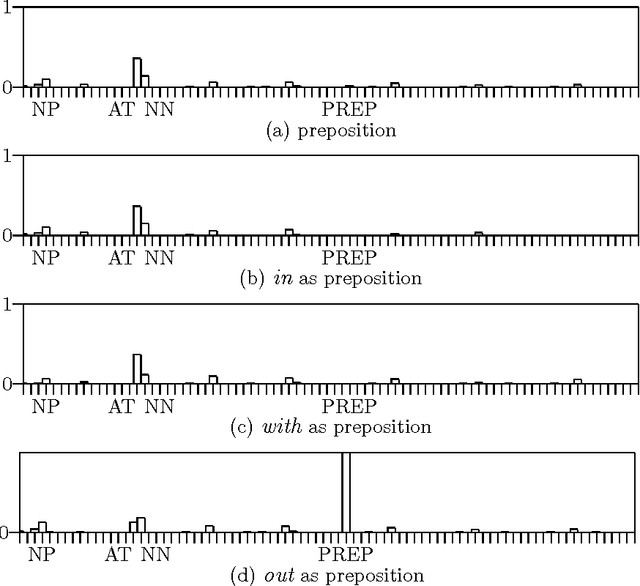
We present a technique which complements Hidden Markov Models by incorporating some lexicalized states representing syntactically uncommon words. Our approach examines the distribution of transitions, selects the uncommon words, and makes lexicalized states for the words. We performed a part-of-speech tagging experiment on the Brown corpus to evaluate the resultant language model and discovered that this technique improved the tagging accuracy by 0.21% at the 95% level of confidence.
* Proceedings of the 1999 Joint SIGDAT Conference on Empirical
Methods in Natural Language Processing and Very Large Corpora, pp.121-127,
1999 * 7 pages, 6 figures
View paper on