 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHinGE: A Dataset for Generation and Evaluation of Code-Mixed Hinglish Text
Paper and Code
Jul 08, 2021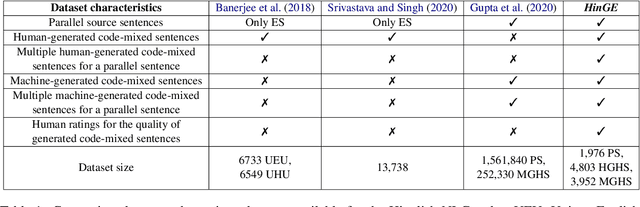



Text generation is a highly active area of research in the computational linguistic community. The evaluation of the generated text is a challenging task and multiple theories and metrics have been proposed over the years. Unfortunately, text generation and evaluation are relatively understudied due to the scarcity of high-quality resources in code-mixed languages where the words and phrases from multiple languages are mixed in a single utterance of text and speech. To address this challenge, we present a corpus (HinGE) for a widely popular code-mixed language Hinglish (code-mixing of Hindi and English languages). HinGE has Hinglish sentences generated by humans as well as two rule-based algorithms corresponding to the parallel Hindi-English sentences. In addition, we demonstrate the inefficacy of widely-used evaluation metrics on the code-mixed data. The HinGE dataset will facilitate the progress of natural language generation research in code-mixed languages.