 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighway and Residual Networks learn Unrolled Iterative Estimation
Paper and Code
Mar 14, 2017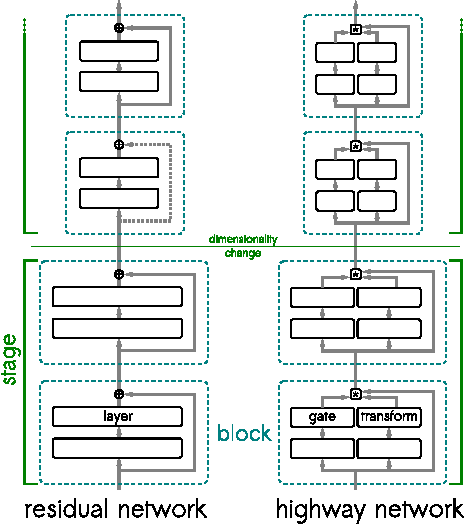

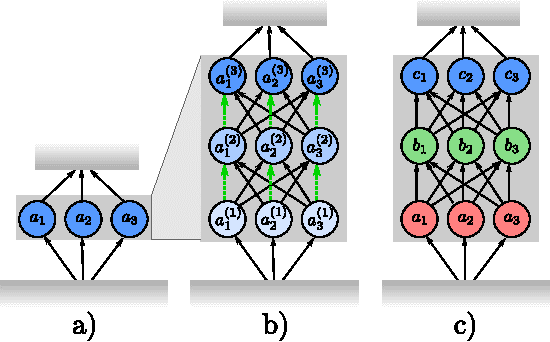
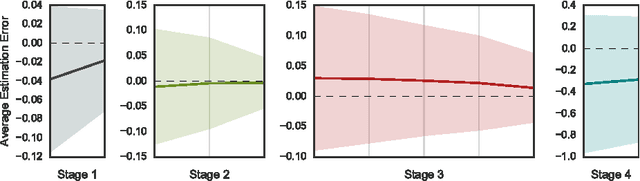
The past year saw the introduction of new architectures such as Highway networks and Residual networks which, for the first time, enabled the training of feedforward networks with dozens to hundreds of layers using simple gradient descent. While depth of representation has been posited as a primary reason for their success, there are indications that these architectures defy a popular view of deep learning as a hierarchical computation of increasingly abstract features at each layer. In this report, we argue that this view is incomplete and does not adequately explain several recent findings. We propose an alternative viewpoint based on unrolled iterative estimation -- a group of successive layers iteratively refine their estimates of the same features instead of computing an entirely new representation. We demonstrate that this viewpoint directly leads to the construction of Highway and Residual networks. Finally we provide preliminary experiments to discuss the similarities and differences between the two architectures.