 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Dimensional Bayesian Optimization with Manifold Gaussian Processes
Paper and Code
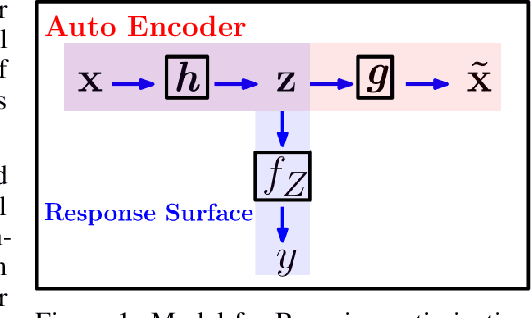
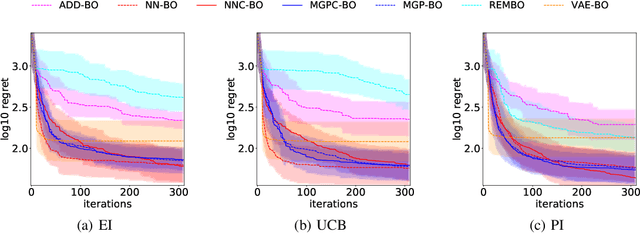


Bayesian optimization (BO) is a powerful approach for seeking the global optimum of expensive black-box functions and has proven successful for fine tuning hyper-parameters of machine learning models. The Bayesian optimization routine involves learning a response surface and maximizing a score to select the most valuable inputs to be queried at the next iteration. These key steps are subject to the curse of dimensionality so that Bayesian optimization does not scale beyond 10--20 parameters. In this work, we address this issue and propose a high-dimensional BO method that learns a nonlinear low-dimensional manifold of the input space. We achieve this with a multi-layer neural network embedded in the covariance function of a Gaussian process. This approach applies unsupervised dimensionality reduction as a byproduct of a supervised regression solution. This also allows exploiting data efficiency of Gaussian process models in a Bayesian framework. We also introduce a nonlinear mapping from the manifold to the high-dimensional space based on multi-output Gaussian processes and jointly train it end-to-end via marginal likelihood maximization. We show this intrinsically low-dimensional optimization outperforms recent baselines in high-dimensional BO literature on a set of benchmark functions in 60 dimensions.