 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Sparse Modeling: A Choice of Two Group Lasso Formulations
Paper and Code
Nov 29, 2017
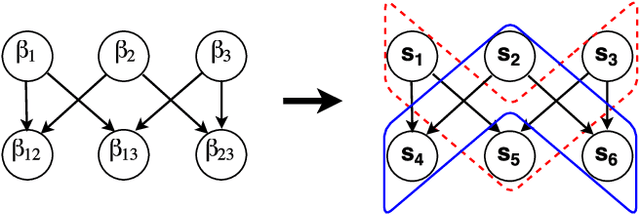

Demanding sparsity in estimated models has become a routine practice in statistics. In many situations, we wish to require that the sparsity patterns attained honor certain problem-specific constraints. Hierarchical sparse modeling (HSM) refers to situations in which these constraints specify that one set of parameters be set to zero whenever another is set to zero. In recent years, numerous papers have developed convex regularizers for this form of sparsity structure, which arises in many areas of statistics including interaction modeling, time series analysis, and covariance estimation. In this paper, we observe that these methods fall into two frameworks, the group lasso (GL) and latent overlapping group lasso (LOG), which have not been systematically compared in the context of HSM. The purpose of this paper is to provide a side-by-side comparison of these two frameworks for HSM in terms of their statistical properties and computational efficiency. We call special attention to GL's more aggressive shrinkage of parameters deep in the hierarchy, a property not shared by LOG. In terms of computation, we introduce a finite-step algorithm that exactly solves the proximal operator of LOG for a certain simple HSM structure; we later exploit this to develop a novel path-based block coordinate descent scheme for general HSM structures. Both algorithms greatly improve the computational performance of LOG. Finally, we compare the two methods in the context of covariance estimation, where we introduce a new sparsely-banded estimator using LOG, which we show achieves the statistical advantages of an existing GL-based method but is simpler to express and more efficient to compute.