 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multi-Task Natural Language Understanding for Cross-domain Conversational AI: HERMIT NLU
Paper and Code

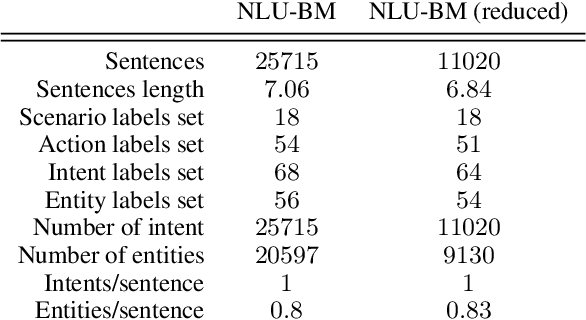
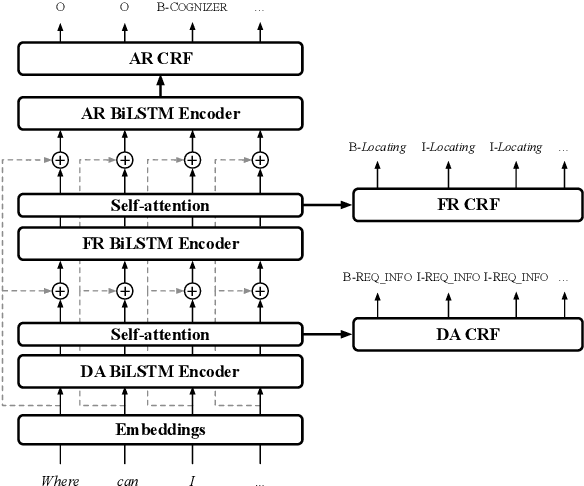
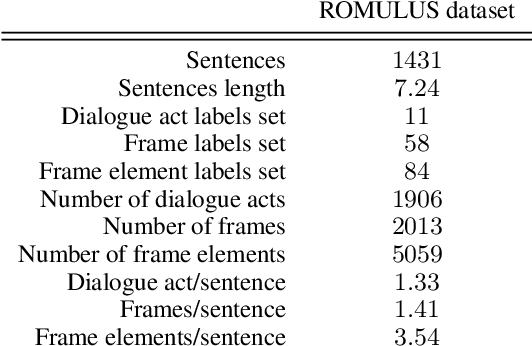
We present a new neural architecture for wide-coverage Natural Language Understanding in Spoken Dialogue Systems. We develop a hierarchical multi-task architecture, which delivers a multi-layer representation of sentence meaning (i.e., Dialogue Acts and Frame-like structures). The architecture is a hierarchy of self-attention mechanisms and BiLSTM encoders followed by CRF tagging layers. We describe a variety of experiments, showing that our approach obtains promising results on a dataset annotated with Dialogue Acts and Frame Semantics. Moreover, we demonstrate its applicability to a different, publicly available NLU dataset annotated with domain-specific intents and corresponding semantic roles, providing overall performance higher than state-of-the-art tools such as RASA, Dialogflow, LUIS, and Watson. For example, we show an average 4.45% improvement in entity tagging F-score over Rasa, Dialogflow and LUIS.