 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Cross-modal Transformer for RGB-D Salient Object Detection
Paper and Code
Feb 16, 2023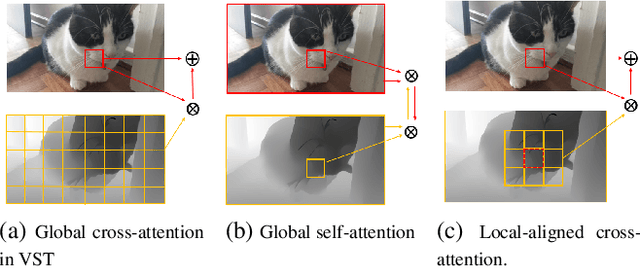
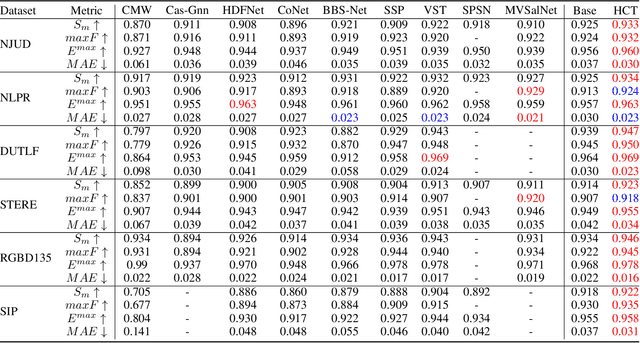
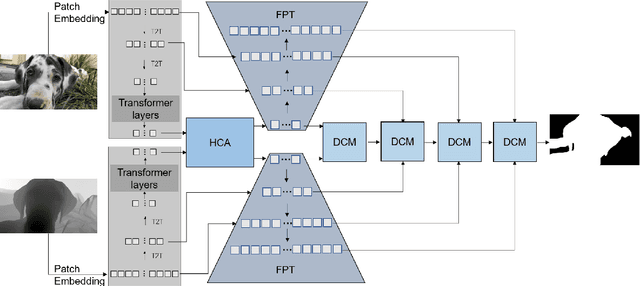
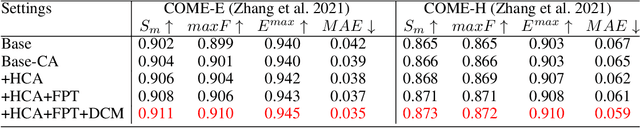
Most of existing RGB-D salient object detection (SOD) methods follow the CNN-based paradigm, which is unable to model long-range dependencies across space and modalities due to the natural locality of CNNs. Here we propose the Hierarchical Cross-modal Transformer (HCT), a new multi-modal transformer, to tackle this problem. Unlike previous multi-modal transformers that directly connecting all patches from two modalities, we explore the cross-modal complementarity hierarchically to respect the modality gap and spatial discrepancy in unaligned regions. Specifically, we propose to use intra-modal self-attention to explore complementary global contexts, and measure spatial-aligned inter-modal attention locally to capture cross-modal correlations. In addition, we present a Feature Pyramid module for Transformer (FPT) to boost informative cross-scale integration as well as a consistency-complementarity module to disentangle the multi-modal integration path and improve the fusion adaptivity. Comprehensive experiments on a large variety of public datasets verify the efficacy of our designs and the consistent improvement over state-of-the-art models.