 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Contrastive Learning with Multiple Augmentation for Sequential Recommendation
Paper and Code
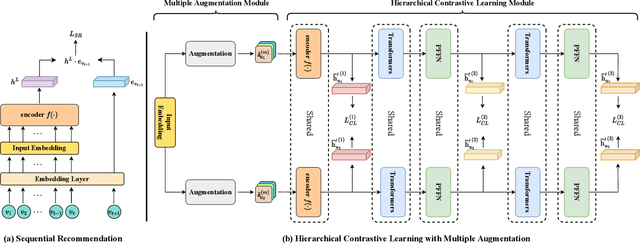


Sequential recommendation addresses the issue of preference drift by predicting the next item based on the user's previous behaviors. Recently, a promising approach using contrastive learning has emerged, demonstrating its effectiveness in recommending items under sparse user-item interactions. Significantly, the effectiveness of combinations of various augmentation methods has been demonstrated in different domains, particularly in computer vision. However, when it comes to augmentation within a contrastive learning framework in sequential recommendation, previous research has only focused on limited conditions and simple structures. Thus, it is still possible to extend existing approaches to boost the effects of augmentation methods by using progressed structures with the combinations of multiple augmentation methods. In this work, we propose a novel framework called Hierarchical Contrastive Learning with Multiple Augmentation for Sequential Recommendation(HCLRec) to overcome the aforementioned limitation. Our framework leverages existing augmentation methods hierarchically to improve performance. By combining augmentation methods continuously, we generate low-level and high-level view pairs. We employ a Transformers-based model to encode the input sequence effectively. Furthermore, we introduce additional blocks consisting of Transformers and position-wise feed-forward network(PFFN) layers to learn the invariance of the original sequences from hierarchically augmented views. We pass the input sequence to subsequent layers based on the number of increment levels applied to the views to handle various augmentation levels. Within each layer, we compute contrastive loss between pairs of views at the same level. Extensive experiments demonstrate that our proposed method outperforms state-of-the-art approaches and that HCLRec is robust even when faced with the problem of sparse interaction.