 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Character Tagger for Short Text Spelling Error Correction
Paper and Code
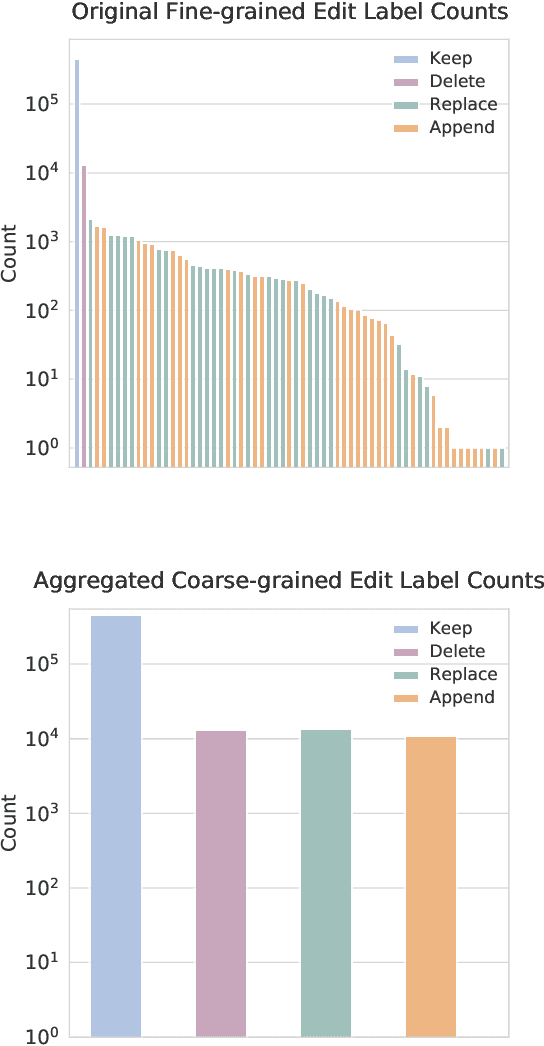

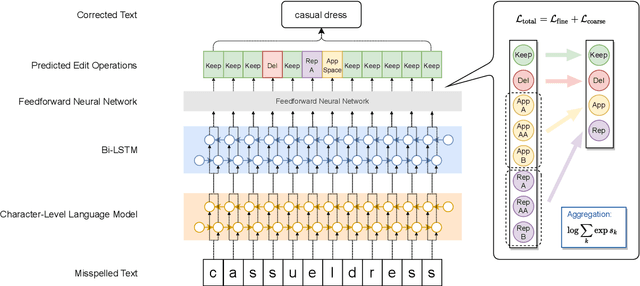
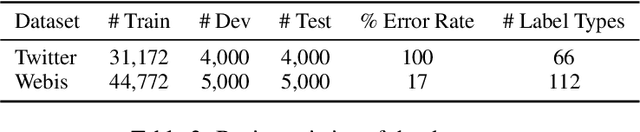
State-of-the-art approaches to spelling error correction problem include Transformer-based Seq2Seq models, which require large training sets and suffer from slow inference time; and sequence labeling models based on Transformer encoders like BERT, which involve token-level label space and therefore a large pre-defined vocabulary dictionary. In this paper we present a Hierarchical Character Tagger model, or HCTagger, for short text spelling error correction. We use a pre-trained language model at the character level as a text encoder, and then predict character-level edits to transform the original text into its error-free form with a much smaller label space. For decoding, we propose a hierarchical multi-task approach to alleviate the issue of long-tail label distribution without introducing extra model parameters. Experiments on two public misspelling correction datasets demonstrate that HCTagger is an accurate and much faster approach than many existing models.