 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden behind the obvious: misleading keywords and implicitly abusive language on social media
Paper and Code
May 03, 2022
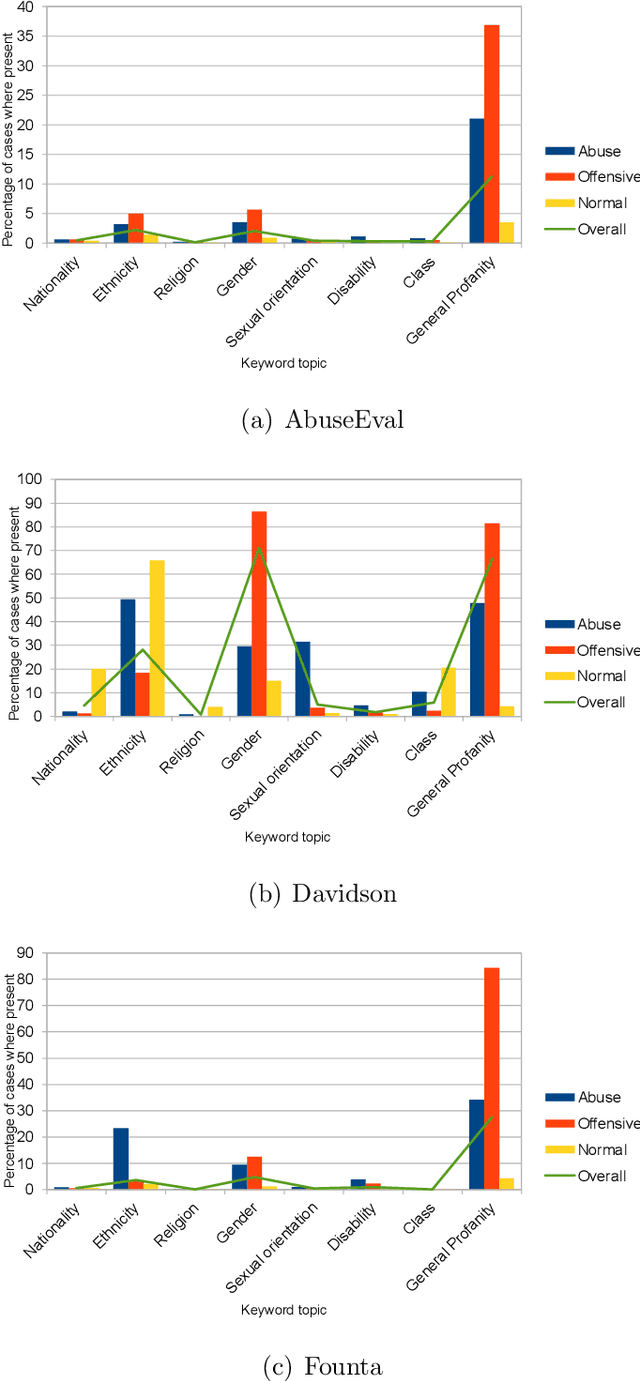

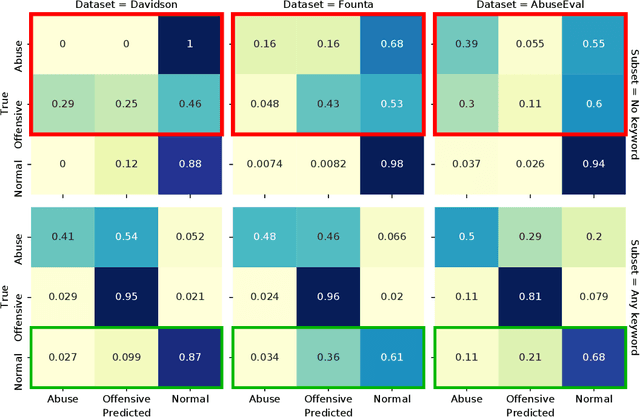
While social media offers freedom of self-expression, abusive language carry significant negative social impact. Driven by the importance of the issue, research in the automated detection of abusive language has witnessed growth and improvement. However, these detection models display a reliance on strongly indicative keywords, such as slurs and profanity. This means that they can falsely (1a) miss abuse without such keywords or (1b) flag non-abuse with such keywords, and that (2) they perform poorly on unseen data. Despite the recognition of these problems, gaps and inconsistencies remain in the literature. In this study, we analyse the impact of keywords from dataset construction to model behaviour in detail, with a focus on how models make mistakes on (1a) and (1b), and how (1a) and (1b) interact with (2). Through the analysis, we provide suggestions for future research to address all three problems.