Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristic Search Value Iteration for POMDPs
Paper and Code
Jul 11, 2012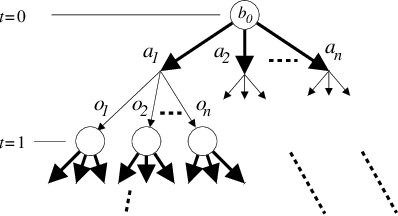
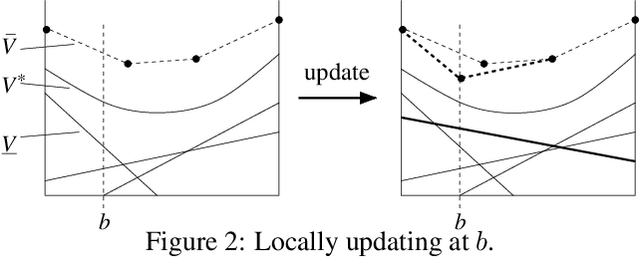
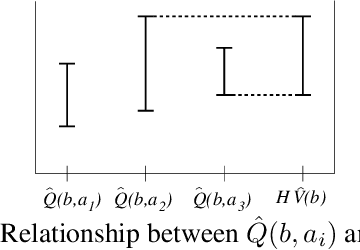
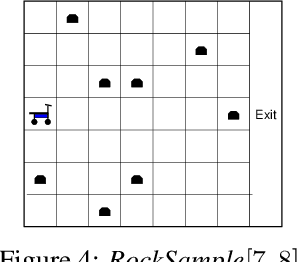
We present a novel POMDP planning algorithm called heuristic search value iteration (HSVI).HSVI is an anytime algorithm that returns a policy and a provable bound on its regret with respect to the optimal policy. HSVI gets its power by combining two well-known techniques: attention-focusing search heuristics and piecewise linear convex representations of the value function. HSVI's soundness and convergence have been proven. On some benchmark problems from the literature, HSVI displays speedups of greater than 100 with respect to other state-of-the-art POMDP value iteration algorithms. We also apply HSVI to a new rover exploration problem 10 times larger than most POMDP problems in the literature.
* Appears in Proceedings of the Twentieth Conference on Uncertainty in
Artificial Intelligence (UAI2004)
View paper on