 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAT: Hardware-Aware Transformers for Efficient Natural Language Processing
Paper and Code
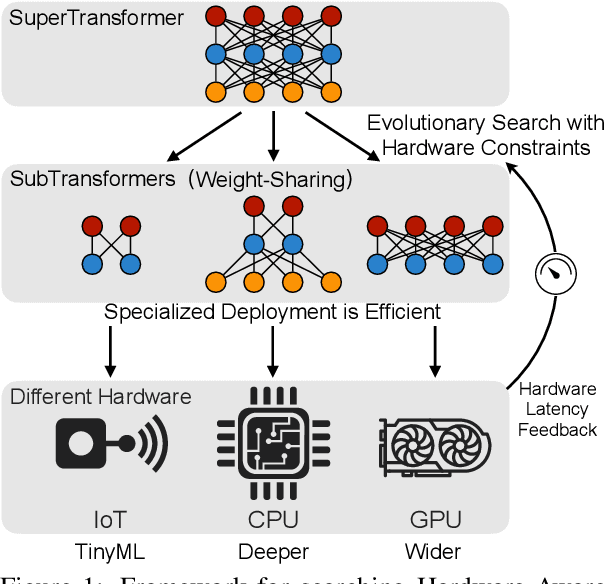
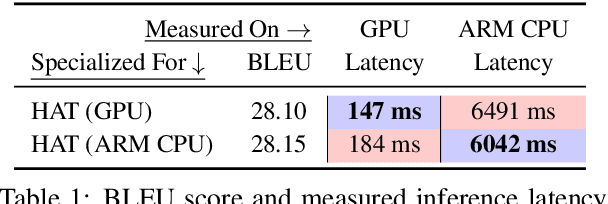
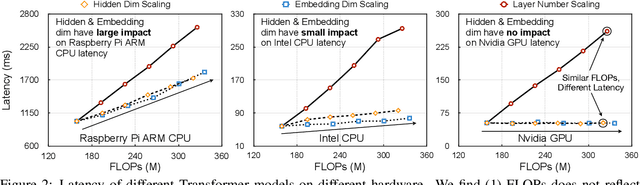
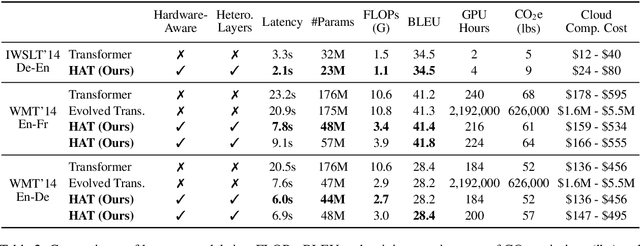
Transformers are ubiquitous in Natural Language Processing (NLP) tasks, but they are difficult to be deployed on hardware due to the intensive computation. To enable low-latency inference on resource-constrained hardware platforms, we propose to design Hardware-Aware Transformers (HAT) with neural architecture search. We first construct a large design space with $\textit{arbitrary encoder-decoder attention}$ and $\textit{heterogeneous layers}$. Then we train a $\textit{SuperTransformer}$ that covers all candidates in the design space, and efficiently produces many $\textit{SubTransformers}$ with weight sharing. Finally, we perform an evolutionary search with a hardware latency constraint to find a specialized $\textit{SubTransformer}$ dedicated to run fast on the target hardware. Extensive experiments on four machine translation tasks demonstrate that HAT can discover efficient models for different hardware (CPU, GPU, IoT device). When running WMT'14 translation task on Raspberry Pi-4, HAT can achieve $\textbf{3}\times$ speedup, $\textbf{3.7}\times$ smaller size over baseline Transformer; $\textbf{2.7}\times$ speedup, $\textbf{3.6}\times$ smaller size over Evolved Transformer with $\textbf{12,041}\times$ less search cost and no performance loss. HAT code is https://github.com/mit-han-lab/hardware-aware-transformers.git