 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHash Embeddings for Efficient Word Representations
Paper and Code
Sep 12, 2017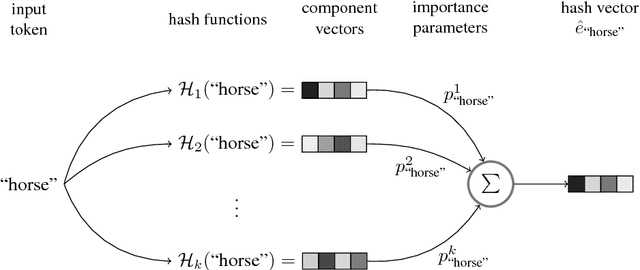

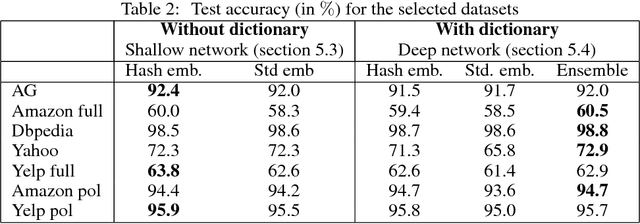
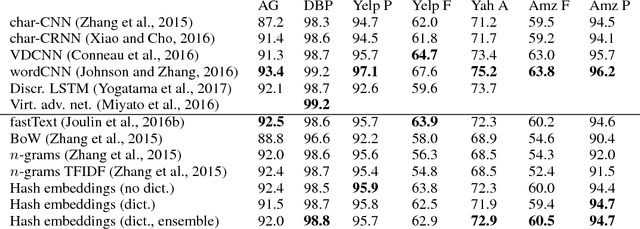
We present hash embeddings, an efficient method for representing words in a continuous vector form. A hash embedding may be seen as an interpolation between a standard word embedding and a word embedding created using a random hash function (the hashing trick). In hash embeddings each token is represented by $k$ $d$-dimensional embeddings vectors and one $k$ dimensional weight vector. The final $d$ dimensional representation of the token is the product of the two. Rather than fitting the embedding vectors for each token these are selected by the hashing trick from a shared pool of $B$ embedding vectors. Our experiments show that hash embeddings can easily deal with huge vocabularies consisting of millions of tokens. When using a hash embedding there is no need to create a dictionary before training nor to perform any kind of vocabulary pruning after training. We show that models trained using hash embeddings exhibit at least the same level of performance as models trained using regular embeddings across a wide range of tasks. Furthermore, the number of parameters needed by such an embedding is only a fraction of what is required by a regular embedding. Since standard embeddings and embeddings constructed using the hashing trick are actually just special cases of a hash embedding, hash embeddings can be considered an extension and improvement over the existing regular embedding types.