 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardness of Deceptive Certificate Selection
Paper and Code
Jun 07, 2023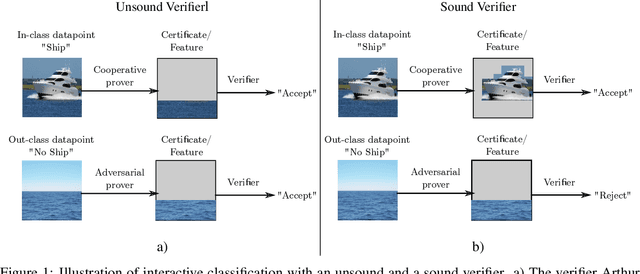
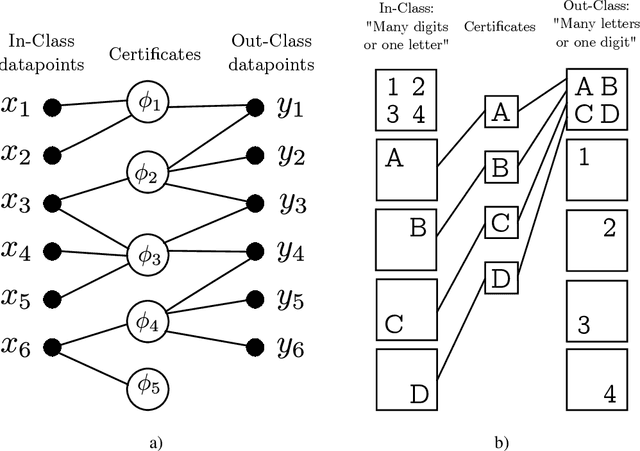
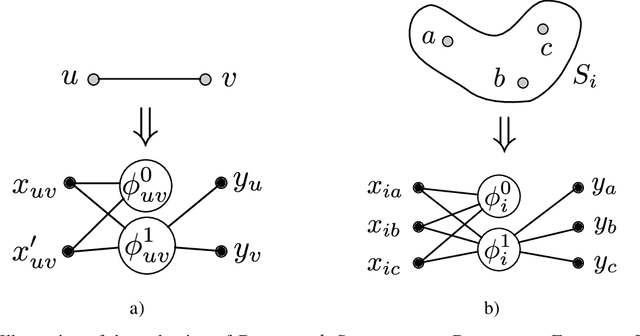
Recent progress towards theoretical interpretability guarantees for AI has been made with classifiers that are based on interactive proof systems. A prover selects a certificate from the datapoint and sends it to a verifier who decides the class. In the context of machine learning, such a certificate can be a feature that is informative of the class. For a setup with high soundness and completeness, the exchanged certificates must have a high mutual information with the true class of the datapoint. However, this guarantee relies on a bound on the Asymmetric Feature Correlation of the dataset, a property that so far is difficult to estimate for high-dimensional data. It was conjectured in W\"aldchen et al. that it is computationally hard to exploit the AFC, which is what we prove here. We consider a malicious prover-verifier duo that aims to exploit the AFC to achieve high completeness and soundness while using uninformative certificates. We show that this task is $\mathsf{NP}$-hard and cannot be approximated better than $\mathcal{O}(m^{1/8 - \epsilon})$, where $m$ is the number of possible certificates, for $\epsilon>0$ under the Dense-vs-Random conjecture. This is some evidence that AFC should not prevent the use of interactive classification for real-world tasks, as it is computationally hard to be exploited.