 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamtajoo: A Persian Plagiarism Checker for Academic Manuscripts
Paper and Code
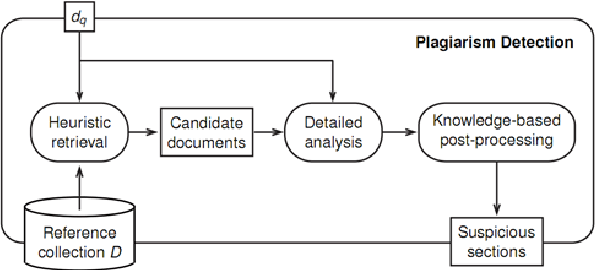
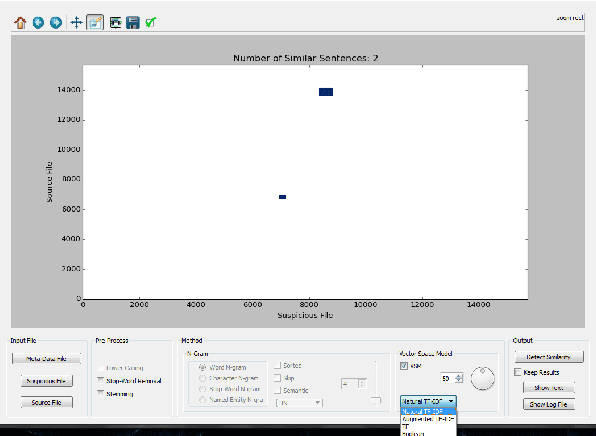
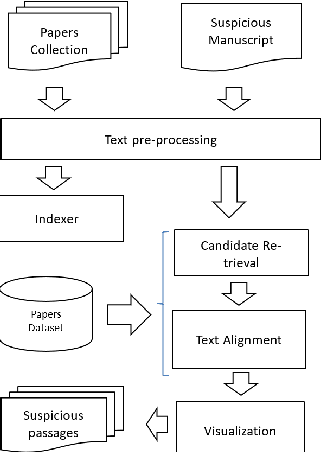
In recent years, due to the high availability of electronic documents through the Web, the plagiarism has become a serious challenge, especially among scholars. Various plagiarism detection systems have been developed to prevent text re-use and to confront plagiarism. Although it is almost easy to detect duplicate text in academic manuscripts, finding patterns of text re-use that has been semantically changed is of great importance. Another important issue is to deal with less resourced languages, which there are low volume of text for training purposes and also low performance in tools for NLP applications. In this paper, we introduce Hamtajoo, a Persian plagiarism detection system for academic manuscripts. Moreover, we describe the overall structure of the system along with the algorithms used in each stage. In order to evaluate the performance of the proposed system, we used a plagiarism detection corpus comply with the PAN standards.