 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHahahahaha, Duuuuude, Yeeessss!: A two-parameter characterization of stretchable words and the dynamics of mistypings and misspellings
Paper and Code
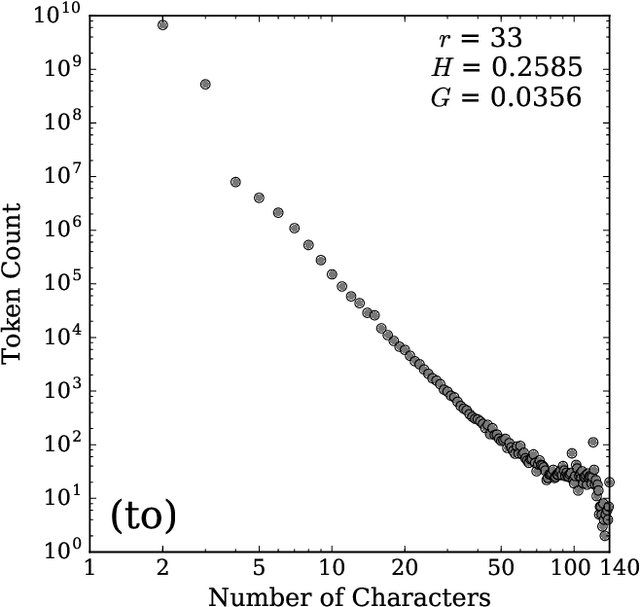

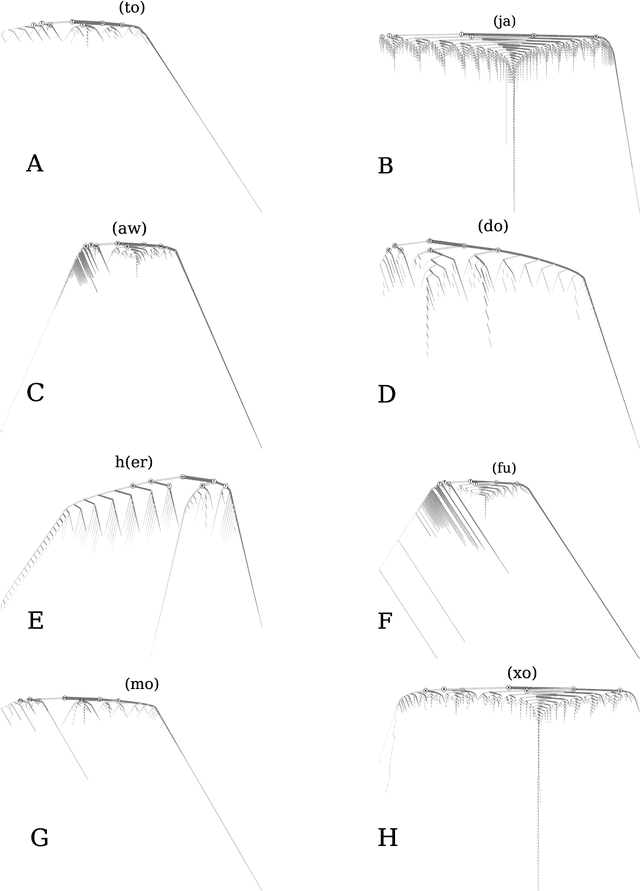
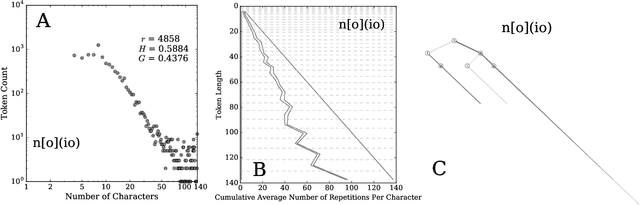
Stretched words like `heellllp' or `heyyyyy' are a regular feature of spoken language, often used to emphasize or exaggerate the underlying meaning of the root word. While stretched words are rarely found in formal written language and dictionaries, they are prevalent within social media. In this paper, we examine the frequency distributions of `stretchable words' found in roughly 100 billion tweets authored over an 8 year period. We introduce two central parameters, `balance' and `stretch', that capture their main characteristics, and explore their dynamics by creating visual tools we call `balance plots' and `spelling trees'. We discuss how the tools and methods we develop here could be used to study the statistical patterns of mistypings and misspellings, along with the potential applications in augmenting dictionaries, improving language processing, and in any area where sequence construction matters, such as genetics.