 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Evolutionary Strategies by Differentiable Robot Simulators
Paper and Code
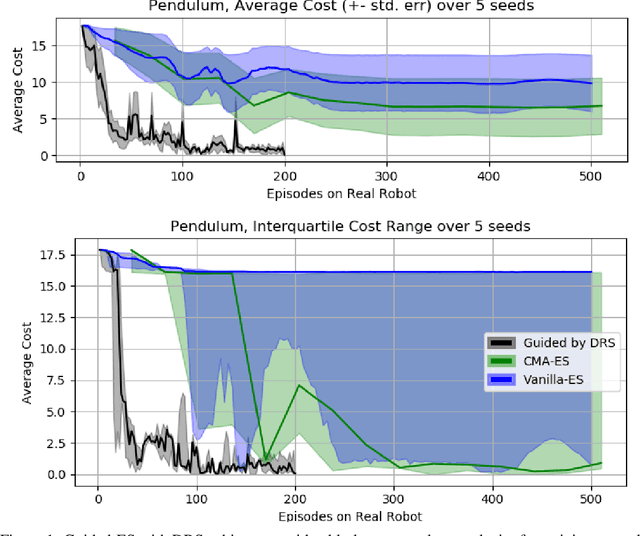
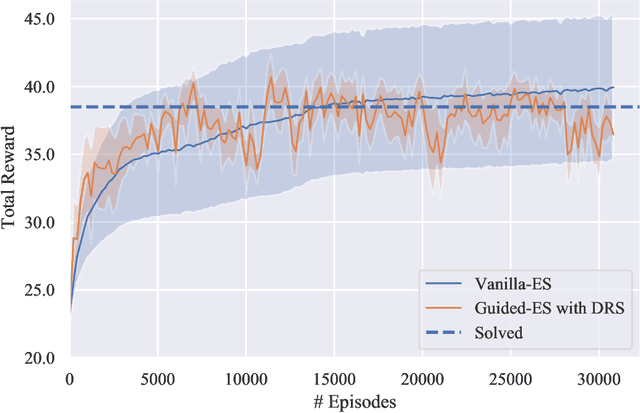

In recent years, Evolutionary Strategies were actively explored in robotic tasks for policy search as they provide a simpler alternative to reinforcement learning algorithms. However, this class of algorithms is often claimed to be extremely sample-inefficient. On the other hand, there is a growing interest in Differentiable Robot Simulators (DRS) as they potentially can find successful policies with only a handful of trajectories. But the resulting gradient is not always useful for the first-order optimization. In this work, we demonstrate how DRS gradient can be used in conjunction with Evolutionary Strategies. Preliminary results suggest that this combination can reduce sample complexity of Evolutionary Strategies by 3x-5x times in both simulation and the real world.