 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Diffusion Model for Adversarial Purification
Paper and Code



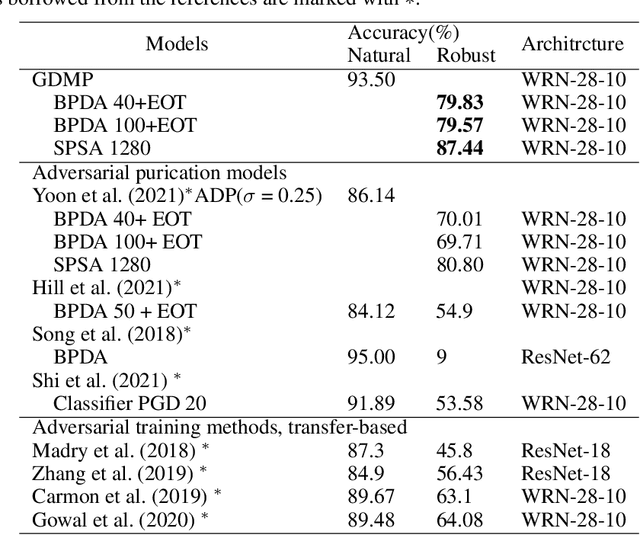
With wider application of deep neural networks (DNNs) in various algorithms and frameworks, security threats have become one of the concerns. Adversarial attacks disturb DNN-based image classifiers, in which attackers can intentionally add imperceptible adversarial perturbations on input images to fool the classifiers. In this paper, we propose a novel purification approach, referred to as guided diffusion model for purification (GDMP), to help protect classifiers from adversarial attacks. The core of our approach is to embed purification into the diffusion denoising process of a Denoised Diffusion Probabilistic Model (DDPM), so that its diffusion process could submerge the adversarial perturbations with gradually added Gaussian noises, and both of these noises can be simultaneously removed following a guided denoising process. On our comprehensive experiments across various datasets, the proposed GDMP is shown to reduce the perturbations raised by adversarial attacks to a shallow range, thereby significantly improving the correctness of classification. GDMP improves the robust accuracy by 5%, obtaining 90.1% under PGD attack on the CIFAR10 dataset. Moreover, GDMP achieves 70.94% robustness on the challenging ImageNet dataset.