 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Validation in Recommender Systems: Framework for Multi-layer Performance Evaluation
Paper and Code
Jul 19, 2022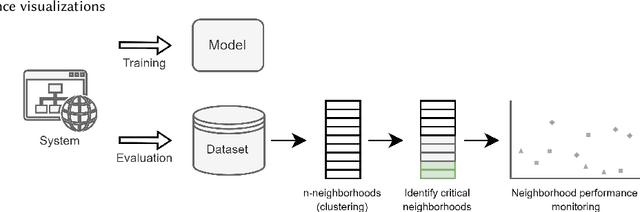
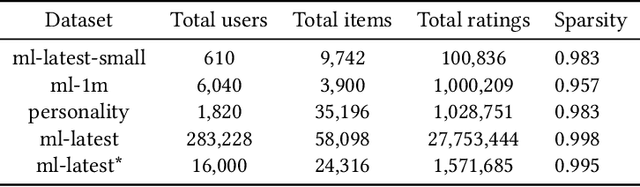
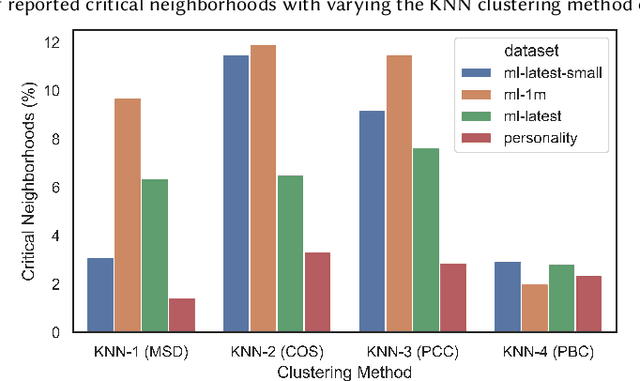

Interpreting the performance results of models that attempt to realize user behavior in platforms that employ recommenders is a big challenge that researchers and practitioners continue to face. Although current evaluation tools possess the capacity to provide solid general overview of a system's performance, they still lack consistency and effectiveness in their use as evident in most recent studies on the topic. Current traditional assessment techniques tend to fail to detect variations that could occur on smaller subsets of the data and lack the ability to explain how such variations affect the overall performance. In this article, we focus on the concept of data clustering for evaluation in recommenders and apply a neighborhood assessment method for the datasets of recommender system applications. This new method, named neighborhood-based evaluation, aids in better understanding critical performance variations in more compact subsets of the system to help spot weaknesses where such variations generally go unnoticed with conventional metrics and are typically averaged out. This new modular evaluation layer complements the existing assessment mechanisms and provides the possibility of several applications to the recommender ecosystem such as model evolution tests, fraud/attack detection and a possibility for hosting a hybrid model setup.