 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Equivariant Deep Reinforcement Learning
Paper and Code
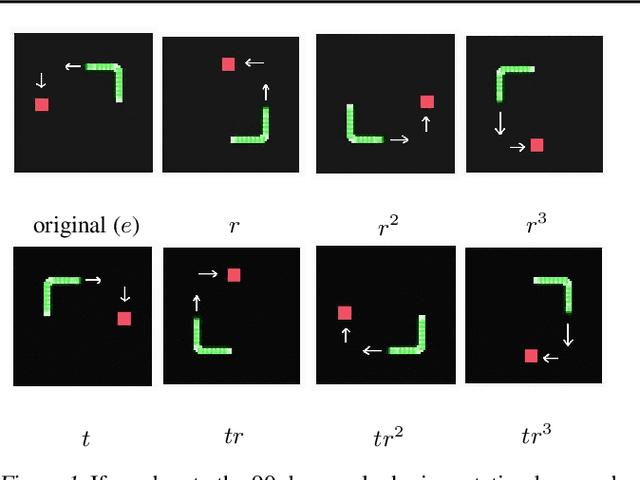
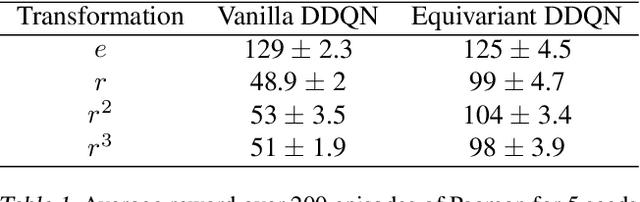
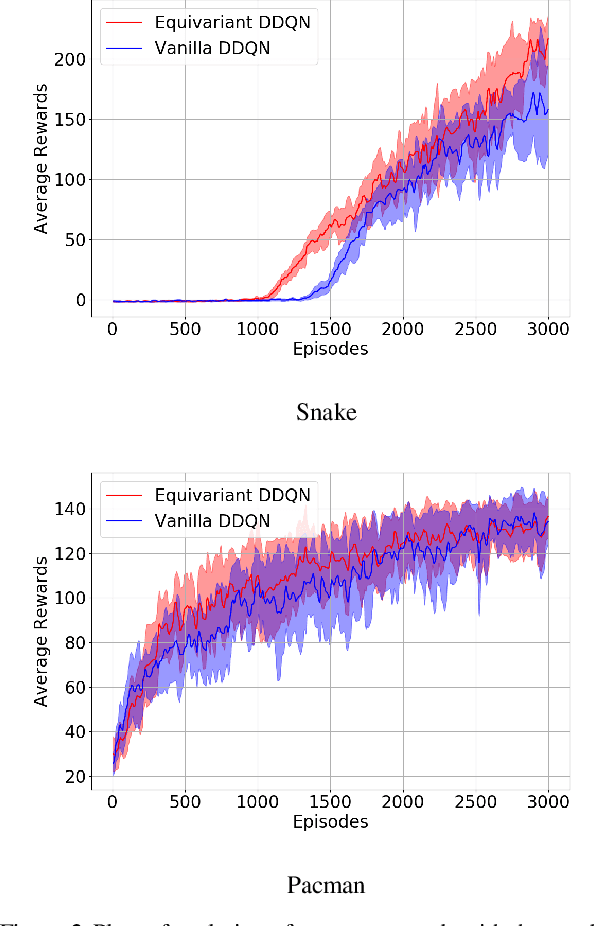
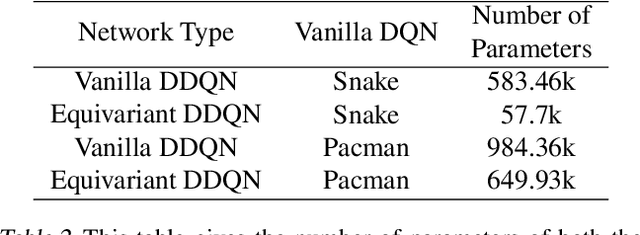
In Reinforcement Learning (RL), Convolutional Neural Networks(CNNs) have been successfully applied as function approximators in Deep Q-Learning algorithms, which seek to learn action-value functions and policies in various environments. However, to date, there has been little work on the learning of symmetry-transformation equivariant representations of the input environment state. In this paper, we propose the use of Equivariant CNNs to train RL agents and study their inductive bias for transformation equivariant Q-value approximation. We demonstrate that equivariant architectures can dramatically enhance the performance and sample efficiency of RL agents in a highly symmetric environment while requiring fewer parameters. Additionally, we show that they are robust to changes in the environment caused by affine transformations.