Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Complex Navigational Instructions Using Scene Graphs
Paper and Code
Jun 03, 2021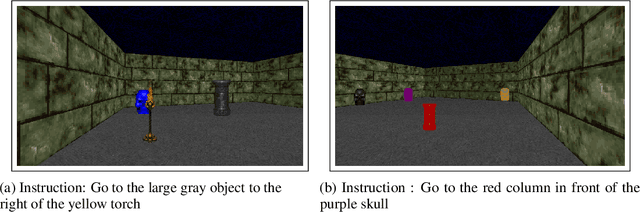
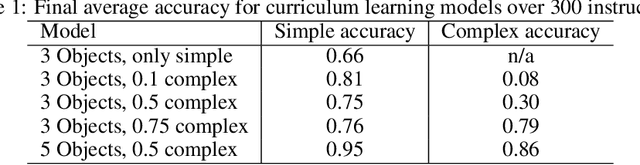
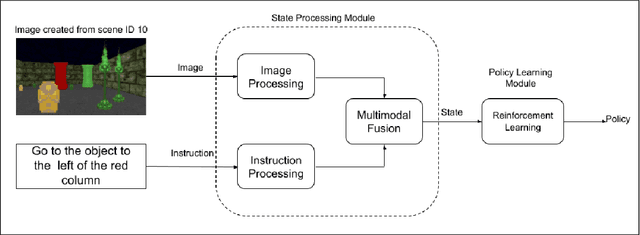
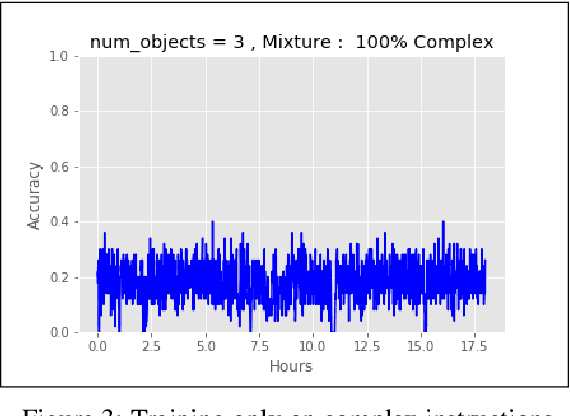
Training a reinforcement learning agent to carry out natural language instructions is limited by the available supervision, i.e. knowing when the instruction has been carried out. We adapt the CLEVR visual question answering dataset to generate complex natural language navigation instructions and accompanying scene graphs, yielding an environment-agnostic supervised dataset. To demonstrate the use of this data set, we map the scenes to the VizDoom environment and use the architecture in \citet{gatedattention} to train an agent to carry out these more complex language instructions.
* arXiv admin note: text overlap with arXiv:1706.07230 by other authors
View paper on