 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroundedness in Retrieval-augmented Long-form Generation: An Empirical Study
Paper and Code
Apr 10, 2024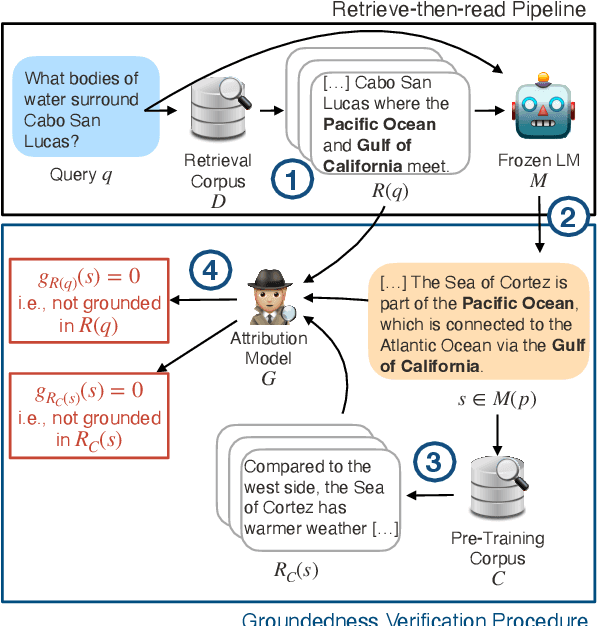
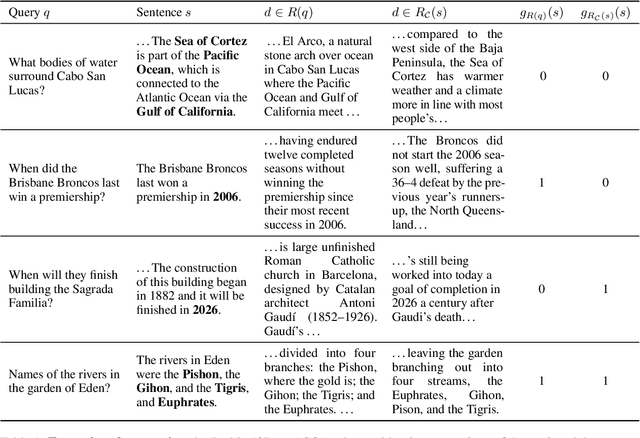
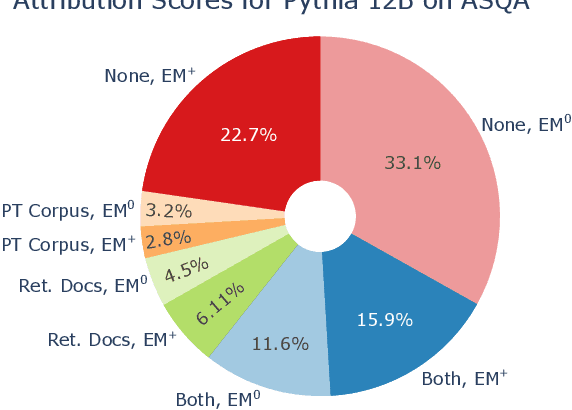

We present an empirical study of groundedness in long-form question answering (LFQA) by retrieval-augmented large language models (LLMs). In particular, we evaluate whether every generated sentence is grounded in the retrieved documents or the model's pre-training data. Across 3 datasets and 4 model families, our findings reveal that a significant fraction of generated sentences are consistently ungrounded, even when those sentences contain correct ground-truth answers. Additionally, we examine the impacts of factors such as model size, decoding strategy, and instruction tuning on groundedness. Our results show that while larger models tend to ground their outputs more effectively, a significant portion of correct answers remains compromised by hallucinations. This study provides novel insights into the groundedness challenges in LFQA and underscores the necessity for more robust mechanisms in LLMs to mitigate the generation of ungrounded content.