 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Discovery of Coordinate Term Relationships between Software Entities
Paper and Code
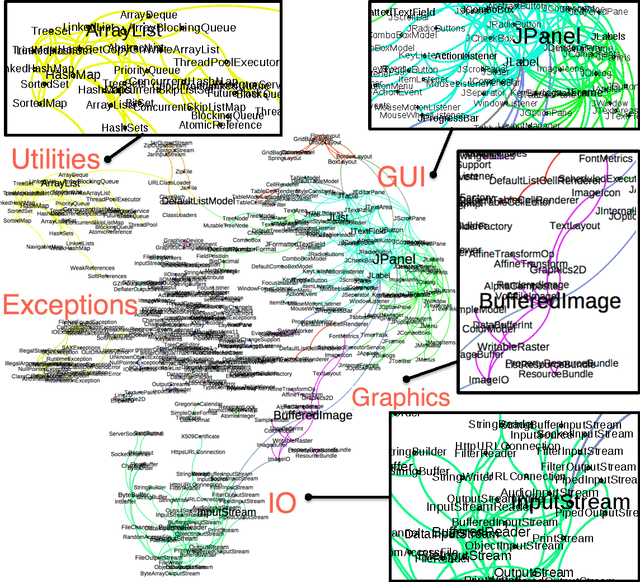
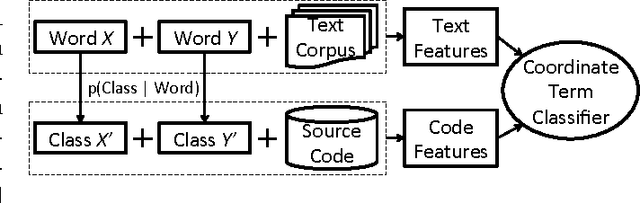

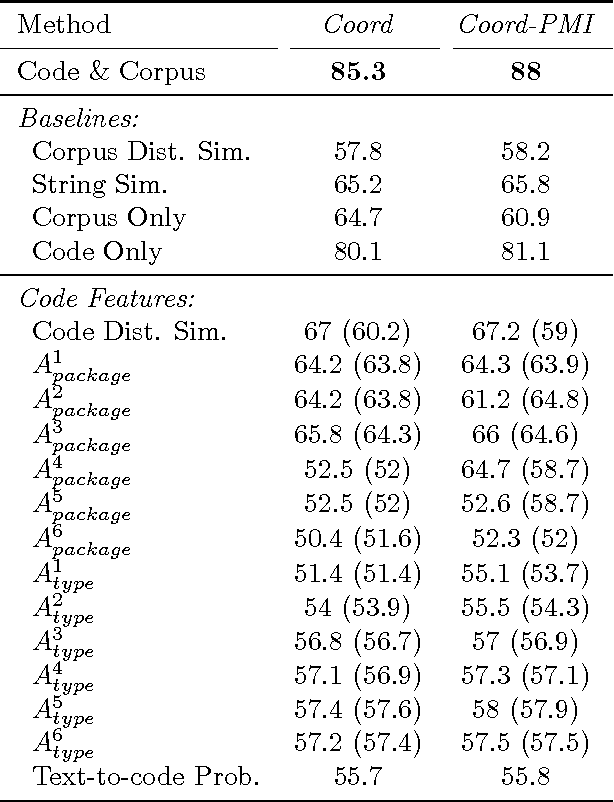
We present an approach for the detection of coordinate-term relationships between entities from the software domain, that refer to Java classes. Usually, relations are found by examining corpus statistics associated with text entities. In some technical domains, however, we have access to additional information about the real-world objects named by the entities, suggesting that coupling information about the "grounded" entities with corpus statistics might lead to improved methods for relation discovery. To this end, we develop a similarity measure for Java classes using distributional information about how they are used in software, which we combine with corpus statistics on the distribution of contexts in which the classes appear in text. Using our approach, cross-validation accuracy on this dataset can be improved dramatically, from around 60% to 88%. Human labeling results show that our classifier has an F1 score of 86% over the top 1000 predicted pairs.