 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGROOT: Corrective Reward Optimization for Generative Sequential Labeling
Paper and Code
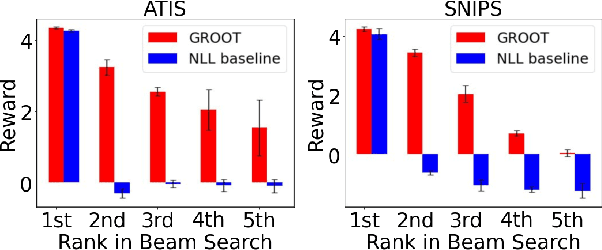

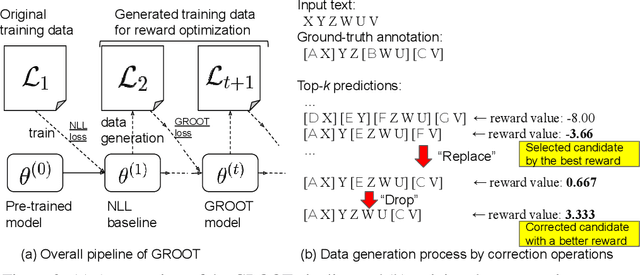
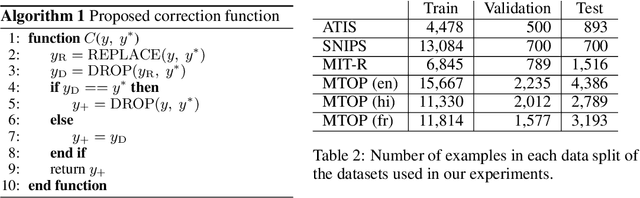
Sequential labeling is a fundamental NLP task, forming the backbone of many applications. Supervised learning of Seq2Seq models (like T5) has shown great success on these problems. However there remains a significant disconnect between the training objectives of these models vs the metrics and desiderata we care about in practical applications. For example, a practical sequence tagging application may want to optimize for a certain precision-recall trade-off (of the top-k predictions) which is quite different from the standard objective of maximizing the likelihood of the gold labeled sequence. Thus to bridge this gap, we propose GROOT -- a simple yet effective framework for Generative Reward Optimization Of Text sequences. GROOT works by training a generative sequential labeling model to match the decoder output distribution with that of the (black-box) reward function. Using an iterative training regime, we first generate prediction candidates, then correct errors in them, and finally contrast those candidates (based on their reward values). As demonstrated via extensive experiments on four public benchmarks, GROOT significantly improves all reward metrics. Furthermore, GROOT also leads to improvements of the overall decoder distribution as evidenced by the quality gains of the top-$k$ candidates.