 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based semi-supervised learning for relational networks
Paper and Code
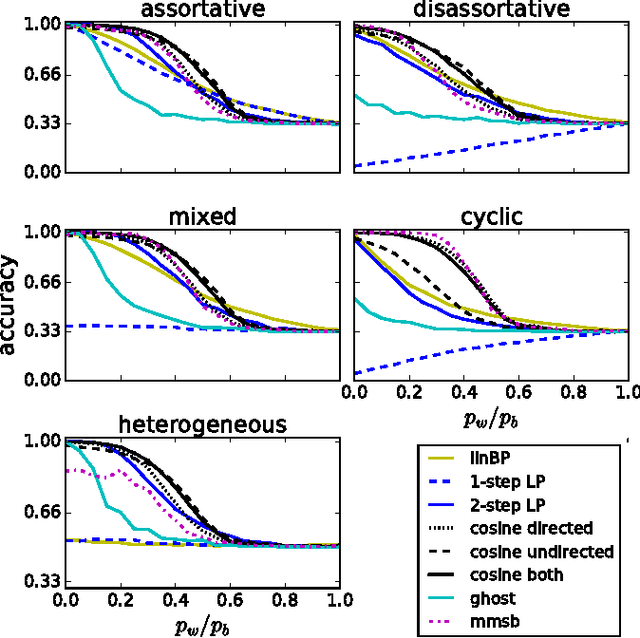
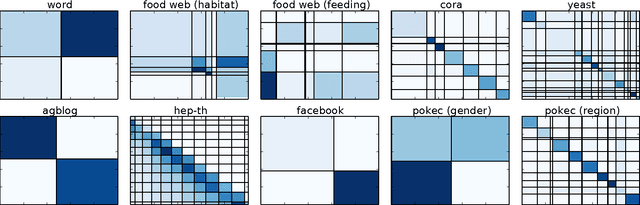
We address the problem of semi-supervised learning in relational networks, networks in which nodes are entities and links are the relationships or interactions between them. Typically this problem is confounded with the problem of graph-based semi-supervised learning (GSSL), because both problems represent the data as a graph and predict the missing class labels of nodes. However, not all graphs are created equally. In GSSL a graph is constructed, often from independent data, based on similarity. As such, edges tend to connect instances with the same class label. Relational networks, however, can be more heterogeneous and edges do not always indicate similarity. For instance, instead of links being more likely to connect nodes with the same class label, they may occur more frequently between nodes with different class labels (link-heterogeneity). Or nodes with the same class label do not necessarily have the same type of connectivity across the whole network (class-heterogeneity), e.g. in a network of sexual interactions we may observe links between opposite genders in some parts of the graph and links between the same genders in others. Performing classification in networks with different types of heterogeneity is a hard problem that is made harder still when we do not know a-priori the type or level of heterogeneity. Here we present two scalable approaches for graph-based semi-supervised learning for the more general case of relational networks. We demonstrate these approaches on synthetic and real-world networks that display different link patterns within and between classes. Compared to state-of-the-art approaches, ours give better classification performance without prior knowledge of how classes interact. In particular, our two-step label propagation algorithm gives consistently good accuracy and runs on networks of over 1.6 million nodes and 30 million edges in around 12 seconds.