 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Descent on Neurons and its Link to Approximate Second-Order Optimization
Paper and Code
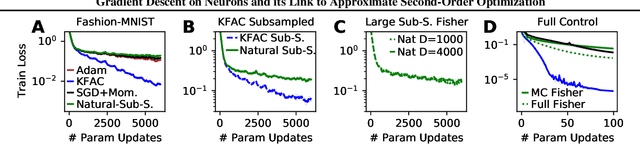
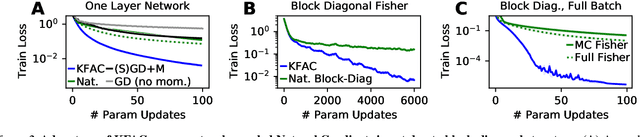
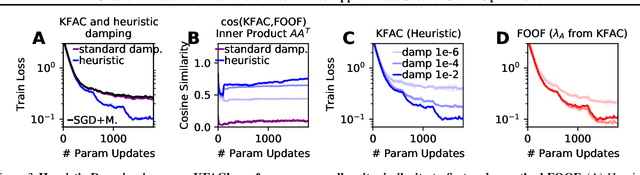
Second-order optimizers are thought to hold the potential to speed up neural network training, but due to the enormous size of the curvature matrix, they typically require approximations to be computationally tractable. The most successful family of approximations are Kronecker-Factored, block-diagonal curvature estimates (KFAC). Here, we combine tools from prior work to evaluate exact second-order updates with careful ablations to establish a surprising result: Due to its approximations, KFAC is not closely related to second-order updates, and in particular, it significantly outperforms true second-order updates. This challenges widely held believes and immediately raises the question why KFAC performs so well. We answer this question by showing that KFAC approximates a first-order algorithm, which performs gradient descent on neurons rather than weights. Finally, we show that this optimizer often improves over KFAC in terms of computational cost and data-efficiency.