 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient and Newton Boosting for Classification and Regression
Paper and Code
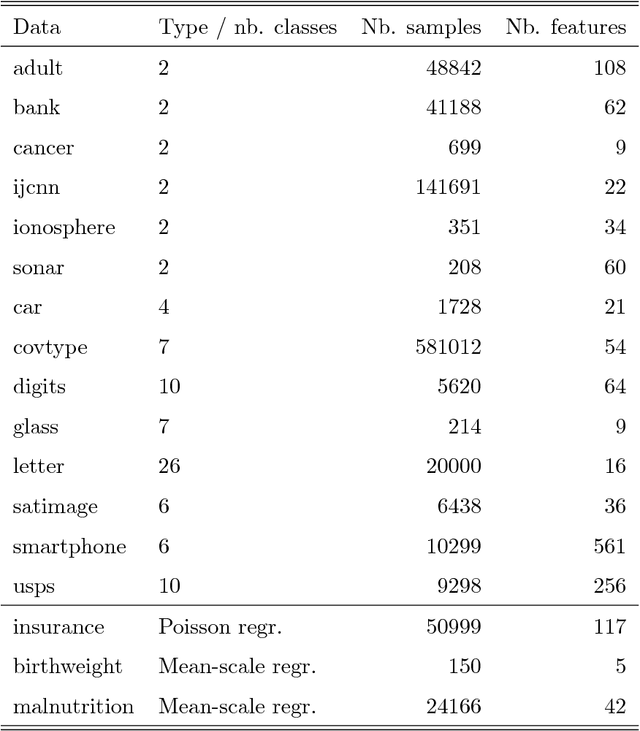
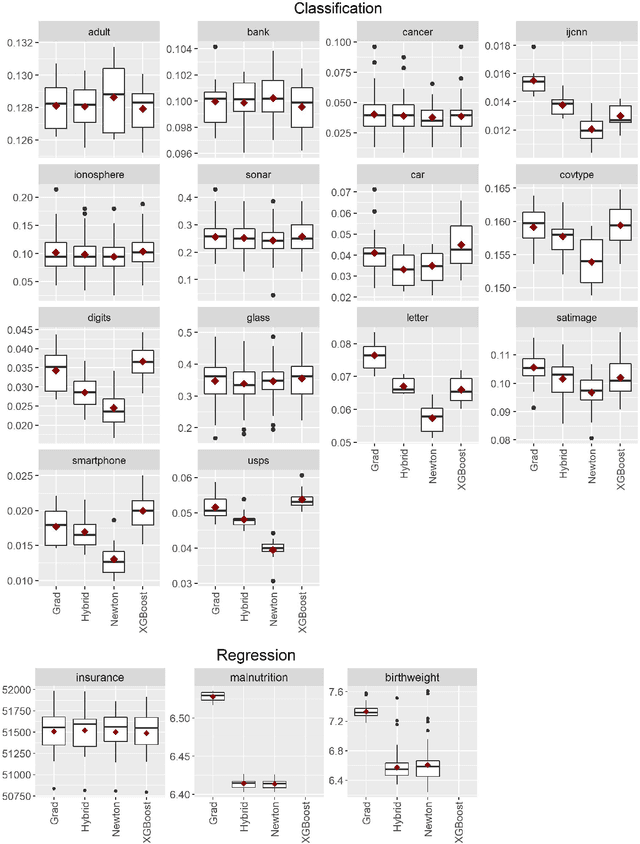
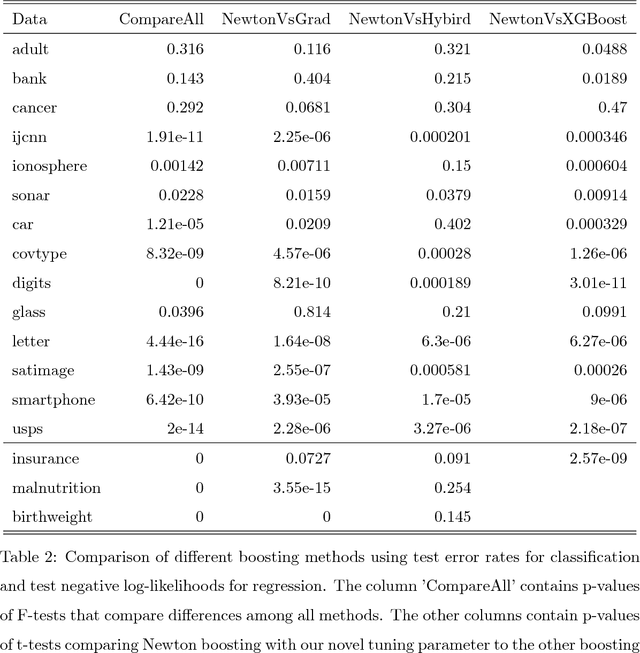
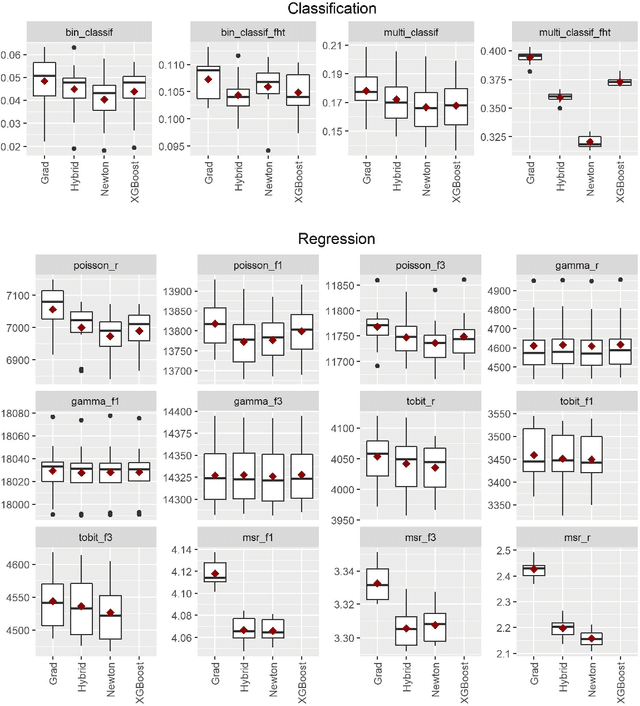
Boosting algorithms enjoy large popularity due to their high predictive accuracy on a wide array of datasets. In this article, we argue that it is important to distinguish between three types of statistical boosting algorithms: gradient and Newton boosting as well as a hybrid variant of the two. To date, both researchers and practitioners often do not discriminate between these boosting variants. We compare the different boosting algorithms on a wide range of real and simulated datasets for various choices of loss functions using trees as base learners. In addition, we introduce a novel tuning parameter for Newton boosting. We find that Newton boosting performs substantially better than the other boosting variants for classification, and that the novel tuning parameter is important for predictive accuracy