 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-Accelerated Policy Optimization via Batch Automatic Differentiation of Gaussian Processes for Real-World Control
Paper and Code
Feb 28, 2022
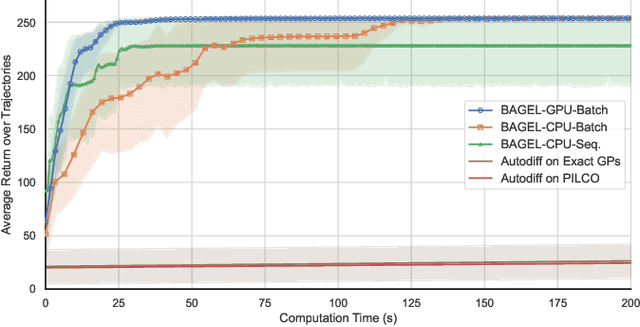
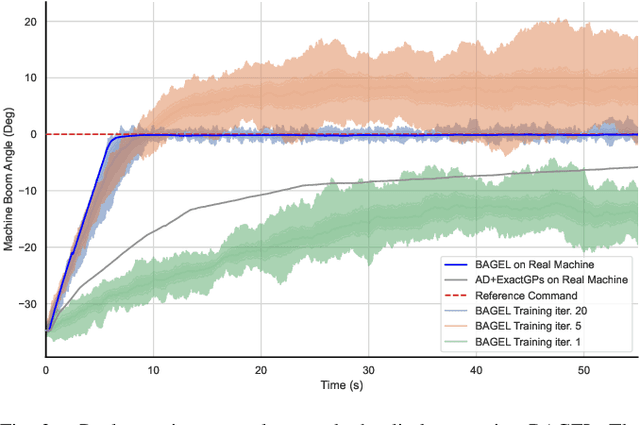
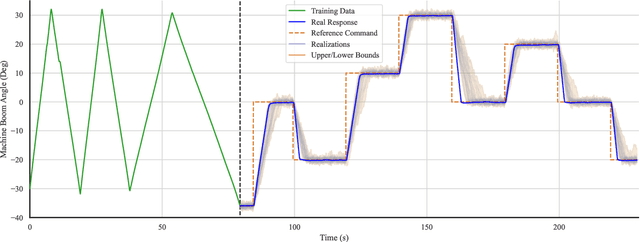
The ability of Gaussian processes (GPs) to predict the behavior of dynamical systems as a more sample-efficient alternative to parametric models seems promising for real-world robotics research. However, the computational complexity of GPs has made policy search a highly time and memory consuming process that has not been able to scale to larger problems. In this work, we develop a policy optimization method by leveraging fast predictive sampling methods to process batches of trajectories in every forward pass, and compute gradient updates over policy parameters by automatic differentiation of Monte Carlo evaluations, all on GPU. We demonstrate the effectiveness of our approach in training policies on a set of reference-tracking control experiments with a heavy-duty machine. Benchmark results show a significant speedup over exact methods and showcase the scalability of our method to larger policy networks, longer horizons, and up to thousands of trajectories with a sublinear drop in speed.