 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-oriented inference of environment from redundant observations
Paper and Code
May 08, 2023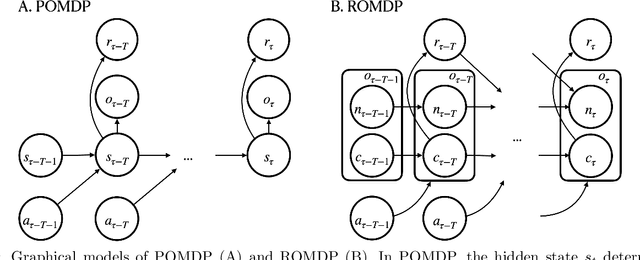
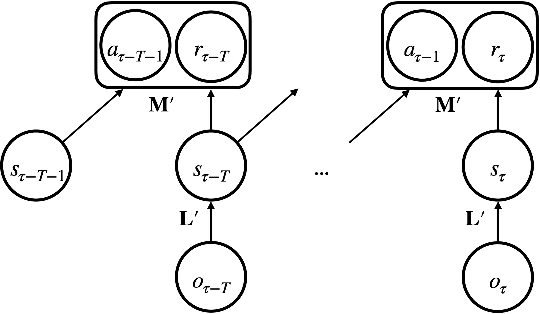
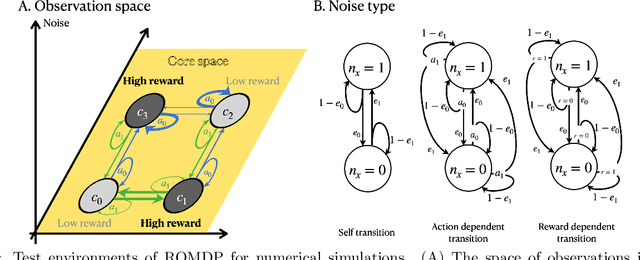
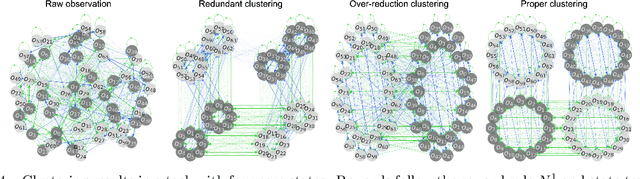
The agent learns to organize decision behavior to achieve a behavioral goal, such as reward maximization, and reinforcement learning is often used for this optimization. Learning an optimal behavioral strategy is difficult under the uncertainty that events necessary for learning are only partially observable, called as Partially Observable Markov Decision Process (POMDP). However, the real-world environment also gives many events irrelevant to reward delivery and an optimal behavioral strategy. The conventional methods in POMDP, which attempt to infer transition rules among the entire observations, including irrelevant states, are ineffective in such an environment. Supposing Redundantly Observable Markov Decision Process (ROMDP), here we propose a method for goal-oriented reinforcement learning to efficiently learn state transition rules among reward-related "core states'' from redundant observations. Starting with a small number of initial core states, our model gradually adds new core states to the transition diagram until it achieves an optimal behavioral strategy consistent with the Bellman equation. We demonstrate that the resultant inference model outperforms the conventional method for POMDP. We emphasize that our model only containing the core states has high explainability. Furthermore, the proposed method suits online learning as it suppresses memory consumption and improves learning speed.