 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Conditioned End-to-End Visuomotor Control for Versatile Skill Primitives
Paper and Code
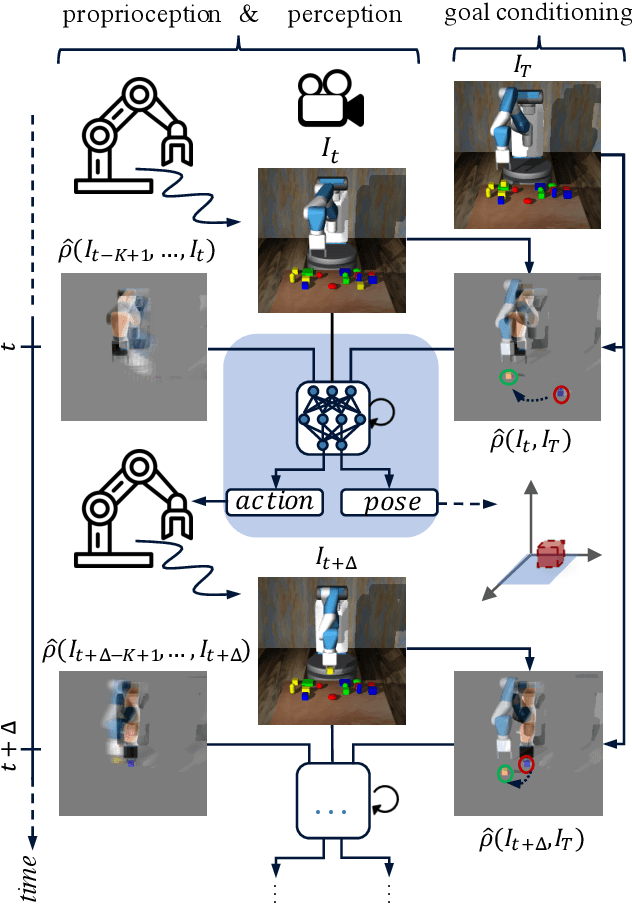
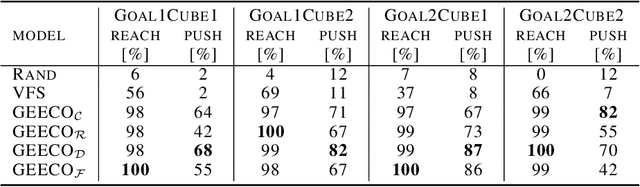
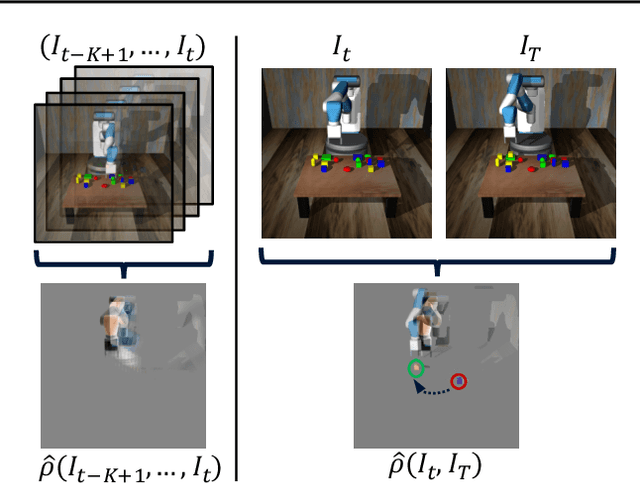
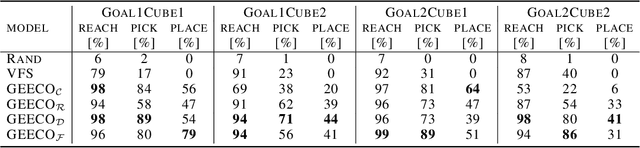
Visuomotor control (VMC) is an effective means of achieving basic manipulation tasks such as pushing or pick-and-place from raw images. Conditioning VMC on desired goal states is a promising way of achieving versatile skill primitives. However, common conditioning schemes either rely on task-specific fine tuning (e.g. using meta-learning) or on sampling approaches using a forward model of scene dynamics i.e. model-predictive control, leaving deployability and planning horizon severely limited. In this paper we propose a conditioning scheme which avoids these pitfalls by learning the controller and its conditioning in an end-to-end manner. Our model predicts complex action sequences based directly on a dynamic image representation of the robot motion and the distance to a given target observation. In contrast to related works, this enables our approach to efficiently perform complex pushing and pick-and-place tasks from raw image observations without predefined control primitives. We report significant improvements in task success over a representative model-predictive controller and also demonstrate our model's generalisation capabilities in challenging, unseen tasks handling unfamiliar objects.