 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlow-WaveGAN 2: High-quality Zero-shot Text-to-speech Synthesis and Any-to-any Voice Conversion
Paper and Code
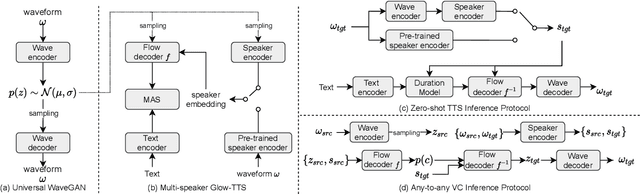
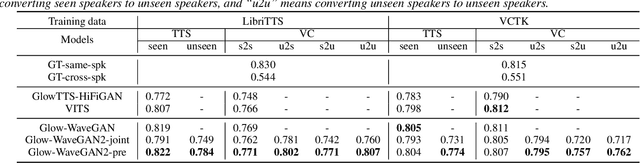
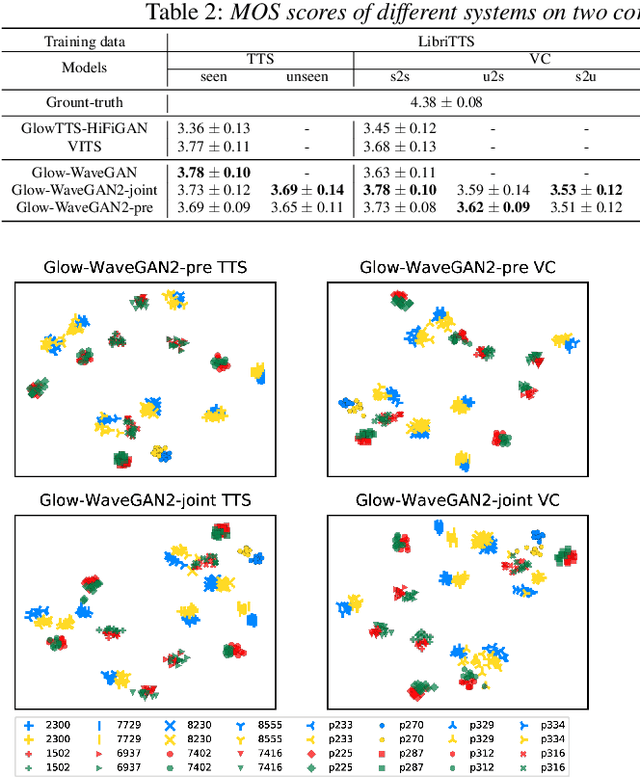
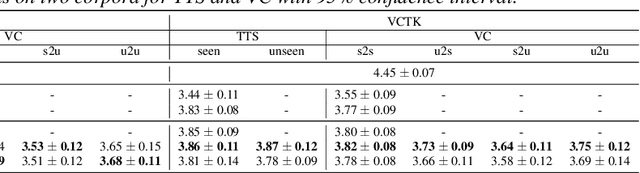
The zero-shot scenario for speech generation aims at synthesizing a novel unseen voice with only one utterance of the target speaker. Although the challenges of adapting new voices in zero-shot scenario exist in both stages -- acoustic modeling and vocoder, previous works usually consider the problem from only one stage. In this paper, we extend our previous Glow-WaveGAN to Glow-WaveGAN 2, aiming to solve the problem from both stages for high-quality zero-shot text-to-speech and any-to-any voice conversion. We first build a universal WaveGAN model for extracting latent distribution $p(z)$ of speech and reconstructing waveform from it. Then a flow-based acoustic model only needs to learn the same $p(z)$ from texts, which naturally avoids the mismatch between the acoustic model and the vocoder, resulting in high-quality generated speech without model fine-tuning. Based on a continuous speaker space and the reversible property of flows, the conditional distribution can be obtained for any speaker, and thus we can further conduct high-quality zero-shot speech generation for new speakers. We particularly investigate two methods to construct the speaker space, namely pre-trained speaker encoder and jointly-trained speaker encoder. The superiority of Glow-WaveGAN 2 has been proved through TTS and VC experiments conducted on LibriTTS corpus and VTCK corpus.