 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting Gender Right in Neural Machine Translation
Paper and Code
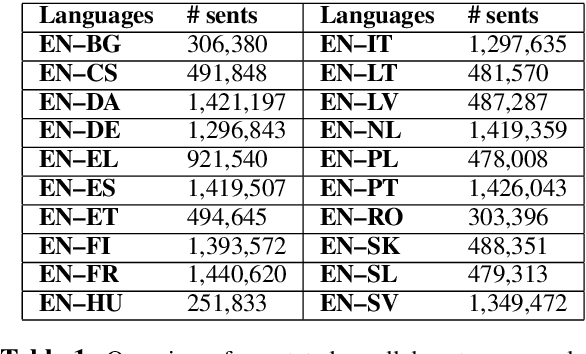


Speakers of different languages must attend to and encode strikingly different aspects of the world in order to use their language correctly (Sapir, 1921; Slobin, 1996). One such difference is related to the way gender is expressed in a language. Saying "I am happy" in English, does not encode any additional knowledge of the speaker that uttered the sentence. However, many other languages do have grammatical gender systems and so such knowledge would be encoded. In order to correctly translate such a sentence into, say, French, the inherent gender information needs to be retained/recovered. The same sentence would become either "Je suis heureux", for a male speaker or "Je suis heureuse" for a female one. Apart from morphological agreement, demographic factors (gender, age, etc.) also influence our use of language in terms of word choices or even on the level of syntactic constructions (Tannen, 1991; Pennebaker et al., 2003). We integrate gender information into NMT systems. Our contribution is two-fold: (1) the compilation of large datasets with speaker information for 20 language pairs, and (2) a simple set of experiments that incorporate gender information into NMT for multiple language pairs. Our experiments show that adding a gender feature to an NMT system significantly improves the translation quality for some language pairs.