 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Methods for Robust Data Analysis in High Dimension
Paper and Code
May 25, 2017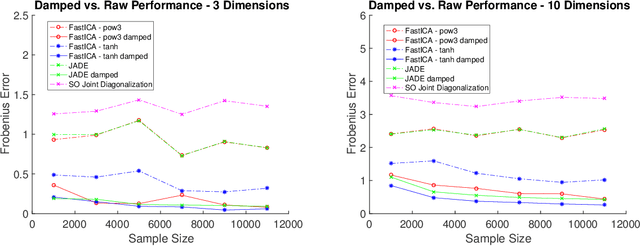
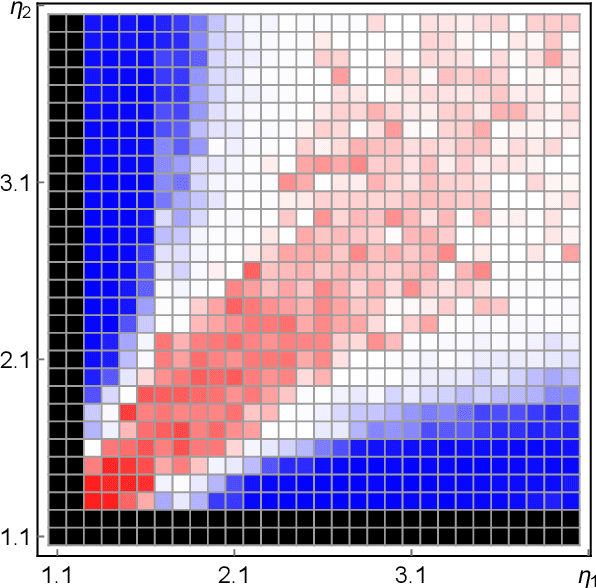
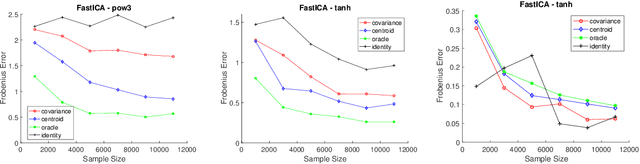
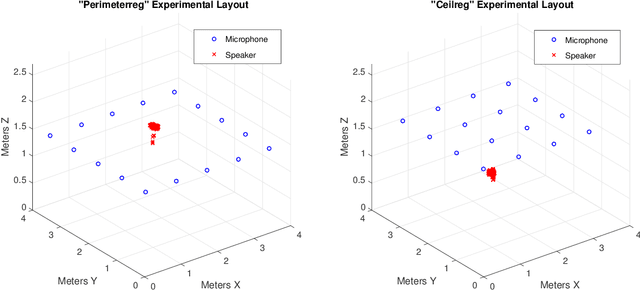
Machine learning and data analysis now finds both scientific and industrial application in biology, chemistry, geology, medicine, and physics. These applications rely on large quantities of data gathered from automated sensors and user input. Furthermore, the dimensionality of many datasets is extreme: more details are being gathered about single user interactions or sensor readings. All of these applications encounter problems with a common theme: use observed data to make inferences about the world. Our work obtains the first provably efficient algorithms for Independent Component Analysis (ICA) in the presence of heavy-tailed data. The main tool in this result is the centroid body (a well-known topic in convex geometry), along with optimization and random walks for sampling from a convex body. This is the first algorithmic use of the centroid body and it is of independent theoretical interest, since it effectively replaces the estimation of covariance from samples, and is more generally accessible. This reduction relies on a non-linear transformation of samples from such an intersection of halfspaces (i.e. a simplex) to samples which are approximately from a linearly transformed product distribution. Through this transformation of samples, which can be done efficiently, one can then use an ICA algorithm to recover the vertices of the intersection of halfspaces. Finally, we again use ICA as an algorithmic primitive to construct an efficient solution to the widely-studied problem of learning the parameters of a Gaussian mixture model. Our algorithm again transforms samples from a Gaussian mixture model into samples which fit into the ICA model and, when processed by an ICA algorithm, result in recovery of the mixture parameters. Our algorithm is effective even when the number of Gaussians in the mixture grows polynomially with the ambient dimension