 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating (Formulaic) Text by Splicing Together Nearest Neighbors
Paper and Code
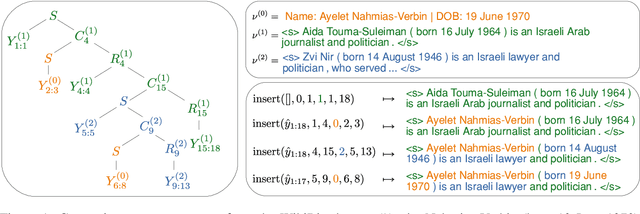
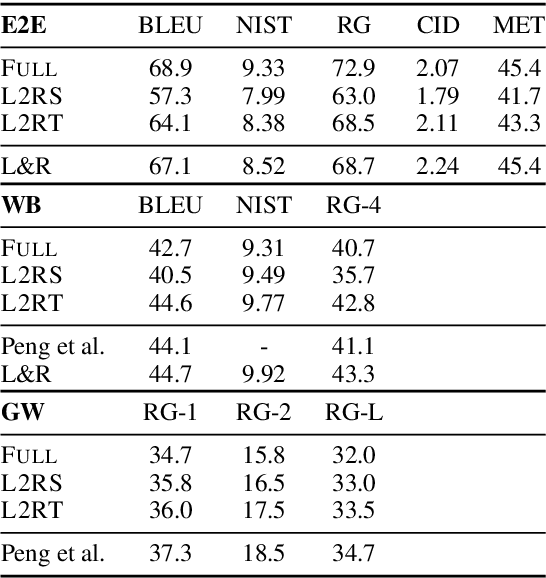
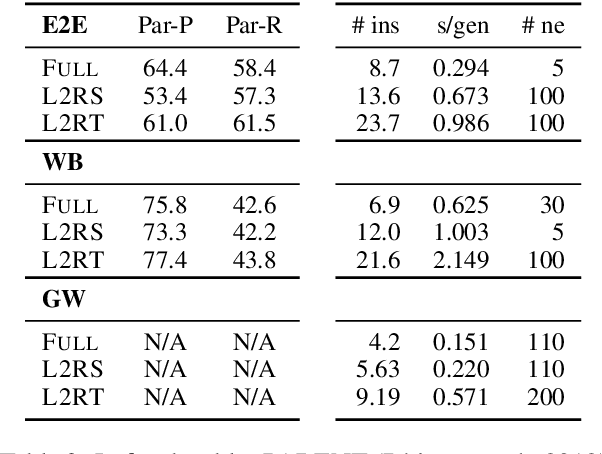
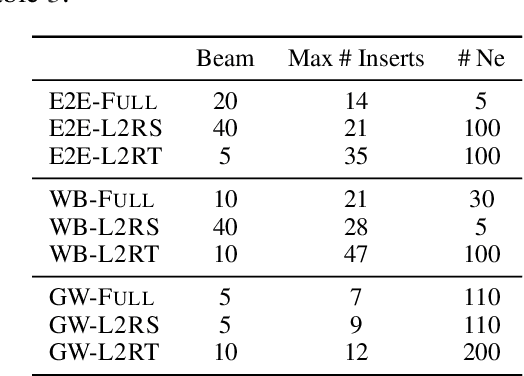
We propose to tackle conditional text generation tasks, especially those which require generating formulaic text, by splicing together segments of text from retrieved "neighbor" source-target pairs. Unlike recent work that conditions on retrieved neighbors in an encoder-decoder setting but generates text token-by-token, left-to-right, we learn a policy that directly manipulates segments of neighbor text (i.e., by inserting or replacing them) to form an output. Standard techniques for training such a policy require an oracle derivation for each generation, and we prove that finding the shortest such derivation can be reduced to parsing under a particular weighted context-free grammar. We find that policies learned in this way allow for interpretable table-to-text or headline generation that is competitive with neighbor-based token-level policies on automatic metrics, though on all but one dataset neighbor-based policies underperform a strong neighborless baseline. In all cases, however, generating by splicing is faster.